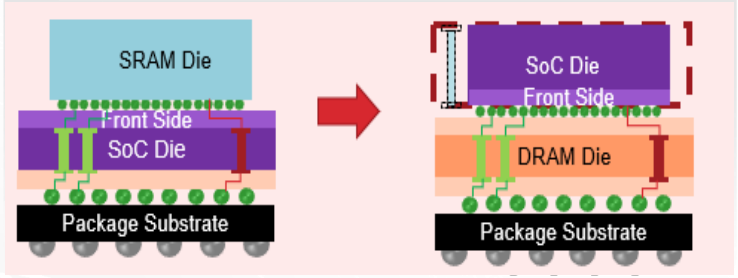
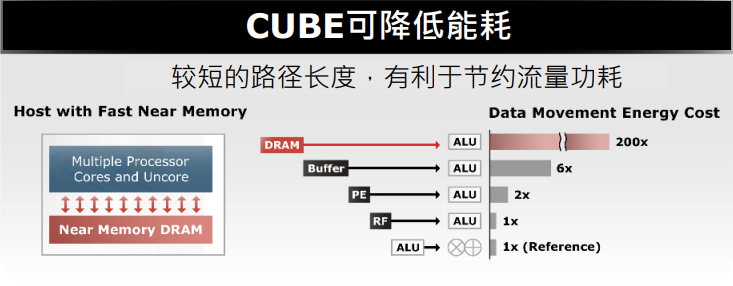
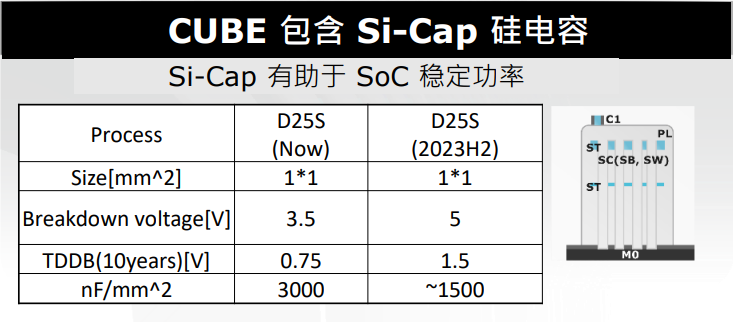
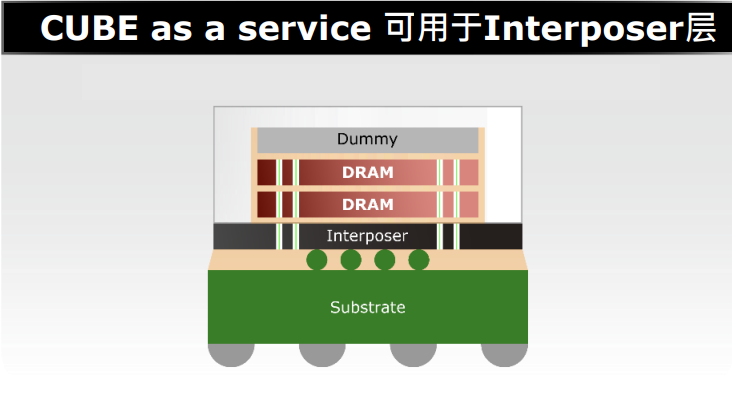
今年2月,华邦宣布加入了UCIe联盟,华邦可协助系统单芯片客户(SoC)设计与 2.5D / 3D 后段工艺(BEOL, back-end-of-life)封装连结。其推出CUBE解决方案,提供半定制化的紧凑超高带宽DRAM(Customized/Compact Ultra Bandwidth Elements)。从CUBE的结构来看,是将SoC裸片置上,DRAM裸片置下,省去SoC的TSV工艺。下图右边虚线部分所示:曾一峻分析,传统上CPU为了增加高速缓存能效,直接增加SRAM的带宽和容量,这样的方式会增加非常高的成本。为了节省成本,厂商会使用相对成熟制程的SRAM,例如5nm的 SoC裸片上堆叠7nm的SRAM 裸片。但这种架构下,底部的CPU就需要埋入相当多的TSV,同时增加CPU裸片面积,成本依然会相对较高,如上图左边的示意。而采用华邦的解决方案(上图右边所示),SoC裸片尺寸缩小,成本相应降低,同时通过华邦的DRAM TSV工艺,可以将SoC的信号引至外部,使它们成为同一个封装芯片。DRAM做TSV的好处是其裸片将会变得很薄,尺寸变得更小。SoC裸片置上也可以带来更好的散热效果,满足现在AI高算力的需求。总之进行3D 堆叠以及CUBE DRAM 裸片堆叠可以带来高带宽、低功耗和优秀的散热表现。华邦的CUBE还可以降低功耗。曾一峻解析,当SoC裸片和DRAM裸片堆叠的时候,相比于传统的引线键合(Wire Bonding),微键合(Micro Bonding)可以将1000微米的线长缩短至40微米,仅有传统长度的2.5%。在未来的混合键合(Hybrid Bonding)封装工艺下,线长甚至可以缩短至1微米。从芯片内部来看,信号所经过的传输距离更短,因此功耗可相应地降低。此外,采用混合键合工艺,两颗堆叠的芯片可以被看作同一颗芯片,因此内部传输信号和SIP表现会更优秀。曾一峻进一步指出,DRAM裸片中都会包含电容,华邦的CUBE芯片提供硅电容(Si-Cap)。硅电容的好处在于可以降低电源波动带来的影响。例如,如果先进制程的SoC的核心电压只有0.75V-1V左右,并且运行过程中电源产生一些波动,除了会影响到功耗,还会影响信号的稳定性,而硅电容容量提高的情况下,SoC借助硅电容就可以获得稳定的电压。下图是华邦当前硅电容规格和制程的进展,今年下半年会带来更优规格的硅电容。通过上面表格的参数,可以看到尽管电容缩小到了一半,但是运行经时击穿电压(TDDB)被提高一倍至1.5V。1.5V目前是大部分先进制程芯片的核心电压。此外击穿电压也是目前先进制程所需的5V,因此1500nF/(mm2)其实是可以符合目前先进制程芯片的电容需求。华邦还提供中介层中介层(Interposer),目前正在进行内部技术演进的是华邦的DRAM堆叠与中介层(Interposer)的架构,以这样的架构开发DRAM的目的是可以验证华邦的TSV。至此,华邦电子成立了3D CaaS平台,可以向客户提供包括DRAM、中介层、硅电容在内的整体解决方案。这也是华邦加入UCIe后带来的贡献之一。“无论是TSV、还是WOW(Wafer on Wafer),华邦都已经达成了与业内相关企业的合作,构建了合作伙伴生态。在COW(Chip on Wafer)方面,华邦将提供TSV的DRAM裸片,并且会帮助SoC客户通过适合的合作伙伴进行后续封测。COW还包含了2.5D、Fan-Out以及3D堆叠工艺,其中2.5D和3D堆叠所用到的硅中介层华邦都可以提供,并且华邦的硅电容还能使芯片的SI/PI减小,使能耗表现更好。甚至华邦的Si-Bridge还能让硅中介层的裸片尺寸更小。”曾一峻说道。
可作为L4级缓存用于边缘计算
华邦的CUBE解决方案主要面向低功耗、高带宽,以及中低容量的内存需求,适合于边缘计算和生成式AI等应用。例如在AI-ISP架构中,如下图所示,灰色部分属于神经网络处理器(NPU),如果AI-ISP要实现大算力,需要很大的带宽,或者是SPRAM。但是在AI-ISP上使用SPRAM的成本非常高,不太可行。如果使用LPDDR4就需要4-8颗,无论是合封还是外置,成本同样相当高昂。此外,还有可能会用到传输速度为4266Mhz的高速LPDDR4,而这样的产品需要依赖7nm或12nm的先进制程工艺生产。华邦的CUBE解决方案可以允许客户使用成熟制程(例如28、22nm)的SoC,获得类似的高速带宽。华邦的CUBE解决方案可以通过多个I/O(256或者512个)结合28nm SoC提供的500MHz的运行频率,以此实现更高带宽,带宽最高可增至256GB/s。不仅如此,华邦在未来可能会和客户探讨64GB/s带宽的合作,I/O数可以减少,裸片的尺寸也会进一步缩小。随着CPU高速运算需求对制程的要求越来越高,我们可以看到16nm、7nm、5nm到3nm的CPU,SRAM占比(如下图中红色部分所示)并不会同比例缩小,因此当需要实现AI运算或者进行高速运算的情况下,就需要把L3的缓存SRAM容量加大,即便可以使用堆叠的方式达到几百MB,也会导致高昂的成本。华邦的方案是把L3缓存缩小,转而使用L4缓存的CUBE解决方案。当然,L4缓存之所以被称作L4,首先是因为它的延迟(Latency)会比L3的稍长。曾一峻表示,为了克服这个问题,可以采用多BANK的方式(multibank per channel),来获得更好的存取效率。第二个方式是将重写(rewrite) IO分开,这是一个比较类SRAM的方式,缩短运行时间。换句话说,是以某些比较特殊的架构进行产品修正,我们会针对客户的一些特殊需求和应用场景进行定制化调配,缩短L4缓存的延迟。同时,AI模型在某些情况下还是需要外置一定容量的内存,例如在某些边缘计算的场景下会需要8-12GB的LPDDR4或者是LPDDR5,因此也可以外挂高容量的工作内存(Working Memory)。综上所述,CUBE可以允许使用成熟制程,以降低SoC成本、减小芯片功耗以及获得高带宽这三大主要诉求。据透露,目前华邦就CUBE解决方案已经和几家客户展开了项目洽谈,具体的合作内容也还处在进行时,包括了边缘计算和生成式AI这两个应用方向。依照目前的进展,或许明年会有一些官方的合作新闻发布。曾一峻认为,CUBE解决方案在边缘计算服务器领域将有很大的机会。相对于大模型的训练,在边缘服务器上可以把模型缩小,但是它一样需要具备很高带宽的内存(通过堆叠DRAM),但不需要很高的容量。无论是监控(surveillance)或5G的边缘计算服务器,或是中小企业内部部署的数据中心服务器(on-premise data server center),都有可能会运用到华邦的CUBE解决方案。






 分享至微信
分享至微信
