

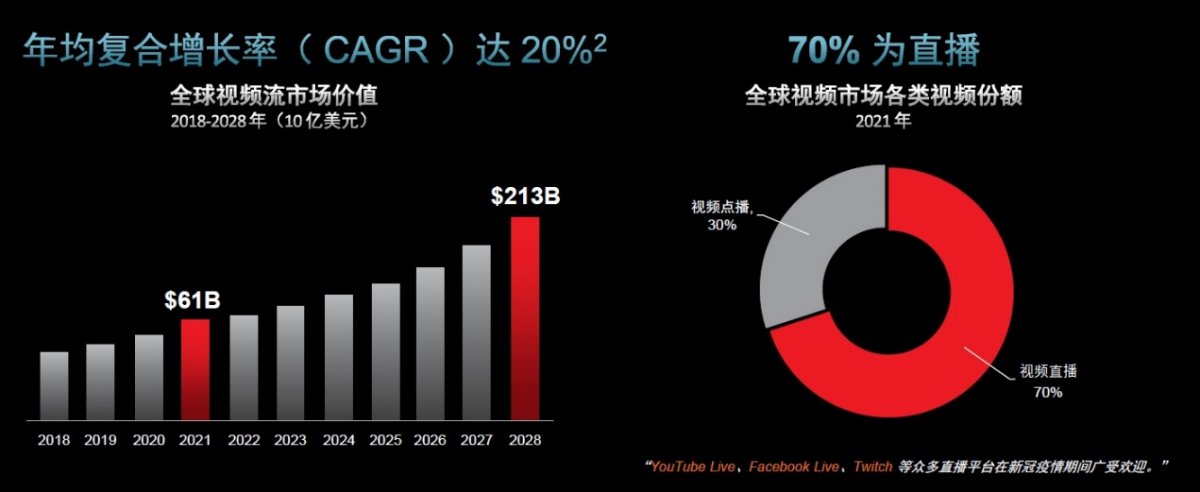
近些年来,视频直播迎来飞速增长。BluewaveConsultingandResearch的数据显示,全球视频流总市值将有望从2021年的610亿美元增长至2028年的2130亿美元,年均复合增长率(CAGR)高达20%。其中,主打视频直播的YouTubeLive、FacebookLive和Twitch用户规模,远远超过其他视频点播和音频平台用户的数量,视频占据了网络流量的70%以上。
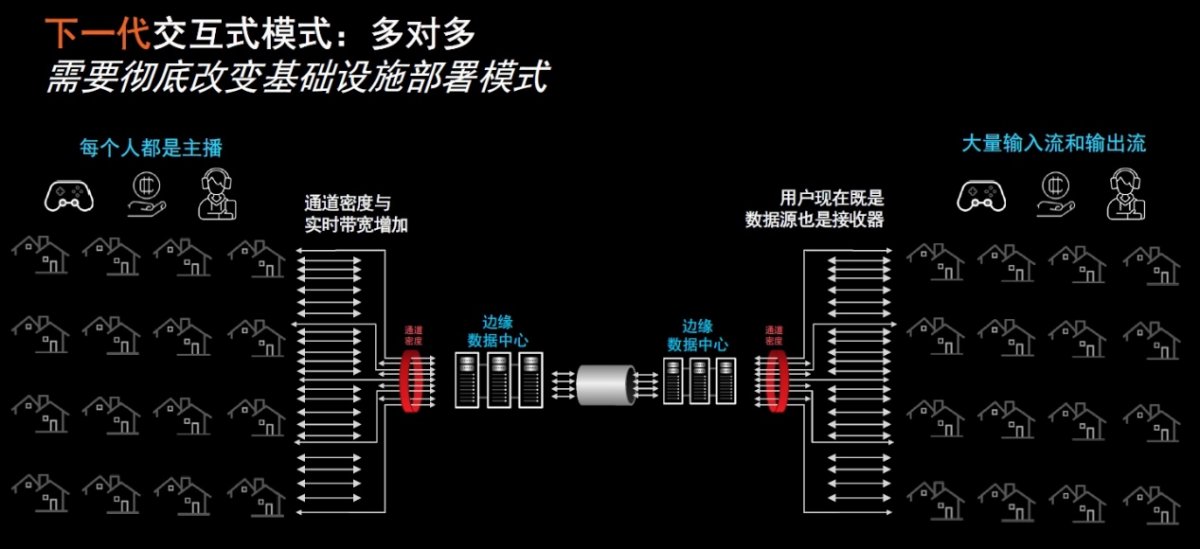
但AMD视频战略与市场开发主管SeanGardner日前在接受《电子工程专辑》采访时指出,传统的广播流媒体主要采取一对多模式,由软件和CPU提供支持。由于视频流数量比较少,时延相对可控,现有基础设施支持传统直播与点播广播是可行的。然而在面对下一代交互式模式(即多对多模式)时,由于连线观赏、直播购物、在线拍卖和社交流媒体等应用场景中的每个人都是主播,他们既是数据源也是接收器,就要求对数据的处理更加贴近用户和网络边缘。

AMD视频战略与市场开发主管Sean Gardner
这样一来,之前通过云集中获得经济效益的传统模式将不复存在,实时、交互式的新型流媒体应用场景要求低时延和大容量,基础设施部署模式需要得到彻底改变才能够适应这些变化带来的成本压力,所有这些都在不断呼唤新一代实时、交互式流媒体解决方案的到来。
揭开全新媒体加速器卡的神秘面纱
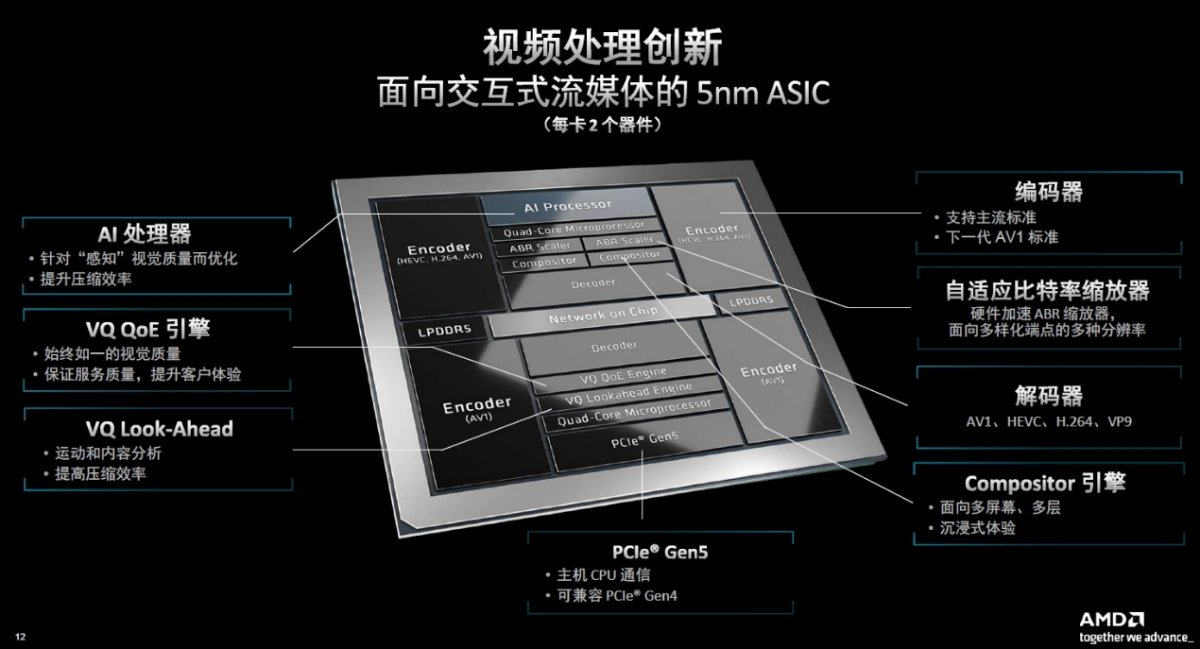
为此,AMD日前推出了全新媒体加速器卡AlveoMA35D。其中,MA代表媒体加速器(MediaAccelerator),35代表AlveoU30后的新一代产品,D表示两个(Dual)5纳米基于ASIC的、支持AV1压缩标准的视频处理单元(VPU),专为推动大规模直播互动流媒体服务新时代而打造。

先简单回顾一下AlveoU30加速卡特性,该卡基于ZynqUltraScale+MPSoC打造,这是一种功耗优化型的全可编程片上系统,集成了用于超高清视频的视频编解码器和图形引擎,可同时支持H.264和HEVC(H.265)编解码器,并且每卡能传输16个1080p30通道。赛灵思方面称,在视频质量方面,AlveoU30加速卡的转码效果不亚于NVIDIAT4,还可以提供更高的密度,系统功耗不到T4的20%。未来,U30高密度PCIe解决方案或将支持机器学习和AI。
2020年,面向电子竞技与游戏直播平台、社交与视频会议、远程直播教育、远程医疗和视频直播等领域,AMD还推出了基于AlveoU30的高通道密度视频转码一体机和基于AlveoU50的超低比特率视频转码一体机,两者均基于AMD实时服务器(RTServer)参考架构,并在当时被称之为面向视频直播的“双管齐下”策略。
与AlveoU30相比,AlveoMA35D的通道密度提高4倍、功耗降低3倍、时延降低4倍、每通道成本最多降低2倍;每卡可以每流1瓦的功率提供多达32路1080p60转码密度,其4K编码时延最低8毫秒,仅为常规处理时间(16毫秒)的一半,22TOPSAI算力(INT8)性能可以支持非常多的创新应用场景,1595美元的建议零售价也非常有吸引力。
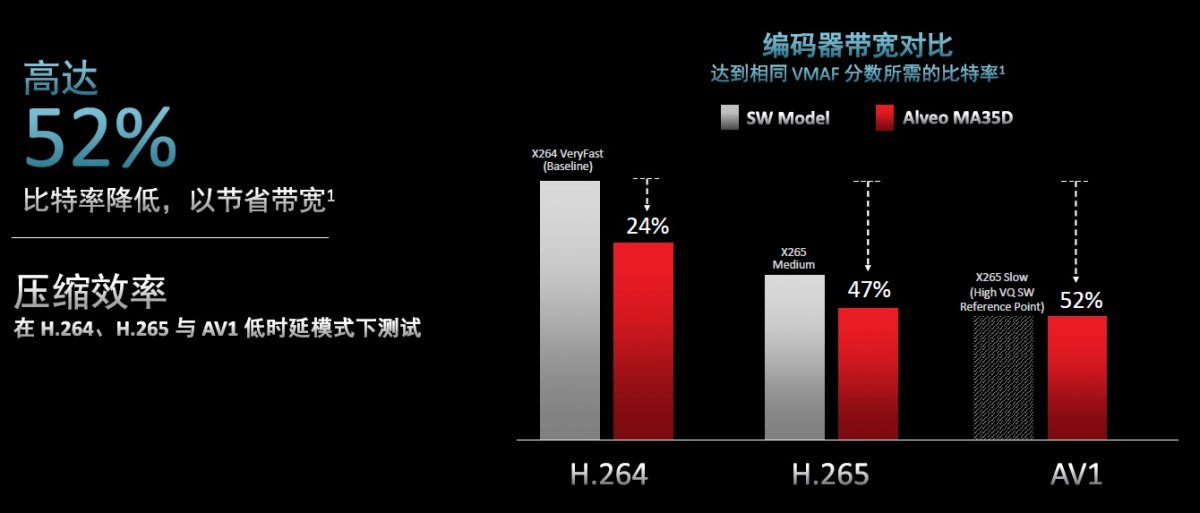
“如何通过高通道密度助力降低资本支出(CAPEX)与运营支出(OPEX),是我们在AlveoMA35D设计之初就重点考虑的问题。”SeanGardner介绍说,客户在评估效率时主要关注每通道成本、每通道面积和每通道功耗三大指标,而配备8张AlveoMA35D卡的1U机架式服务器可提供256个通道,以实现每服务器、每机架或每数据中心转码密度最大化。数据显示,在每通道成本50美元,功耗1瓦的条件下,得益于先进编码解码器的使用,每通道比特率降低了52%。
新的专用视频处理单元(VPU)是AlveoMA35D的核心组件。如下图所示,四个独立的支持AV1压缩标准的编码器(MP)单元模块被部署在芯片四周,通过在视频处理单元上执行所有视频处理功能,可以最大限度减少CPU和加速器之间的数据迁移,进而降低整体时延并实现通道密度最大化,达到每卡高达32路1080p60、8路4Kp60或4路8Kp30的转码密度。
考虑到带宽的消耗对于流媒体客户来说是非常大的一项运营开支,AMD此番也针对主流H.264和H.265编解码器提供了超低时延支持,并配备下一代AV1转码器引擎,每通道比特率降低了52%,以节省带宽。
此外,为了能以更高的效率把动态内容传导给编码器,AlveoMA35D加速器还集成了人工智能(AI)处理器和专用视频质量引擎,能够以更低的带宽提升体验质量。AI处理器会逐帧评估内容并动态调整编码器设置,以提高感知视觉质量,同时最大限度降低比特率。优化技术则包括用于文本和面部分辨率的感兴趣区域(ROI)编码、用于纠正剧烈运动和复杂场景的伪影检测,以及用于比特率优化预测洞察的内容感知编码。
但是,人工智能并不完美,所以在进行动态调整时难免会出现一些不准确,或者是判断失误的情况。为此,AlveoMA35D中还引入了VQ分析IP模块,据称,该IP模块可在人工智能进行动态调整和变化的过程中形成反馈环,以确保所做出的决策是正确的。
“通过VQ分析,我们可以确保每一帧视频的质量,因为一旦出现错误就可以得到及时调整。尽管类似的方案中已经在传统模式中得以应用,但在这种实时、低时延的应用场景中实现还并不多见。“SeanGardner说。
在做视频处理的时候,能够确保成本效益固然重要,但是最重要的是要能够使用这一技术。该平台可通过AMD媒体加速软件开发套件(SDK)访问,支持广泛使用的FFmpeg和Gstreamer视频框架,易于开发。如果某些客户拥有自己的框架,也可以与AlveoMA35D媒体加速器API进行接口连接。
SeanGardner不认为AlveoMA35D会与AMDCPU/GPU形成竞争关系,“它们各有所长,效率非常高,彼此之间互补性极强。“例如CPU可以提供非常高性能的压缩,但如果用CPU处理几百万条流视频,经济性就很差。同理,如果对图像呈现有极高要求的应用场景,GPU显然会是更好的选择;AlveoMA35D更适合在低流媒体功耗、低时延、高质量的编码领域大展身手。

