

被誉为英国半导体之父,同时也是Arm联合创始人的Hermann Hauser先前曾经这样评价过Graphcore:“这在计算机历史上只发生过三次,第一次是70年代的CPU,第二次是90年代的GPU,而Graphcore就是第三次革命。他们的芯片是这个世界伟大新架构的一种。”
当通用计算逐渐在性能、能效比提升逐年放缓的情况下,摩尔定律放缓、登纳德缩放定律失效,被人们每每提及的“架构革新”成为一种必然。Graphcore的IPU可算是当代“架构革命”的先驱之一。Graphcore的架构革命究竟能带来什么?

为什么需要革命?
神经网络(NN)的一大特点,就是在逻辑层面对人脑神经元行为的模拟。更加高度抽象地说,以“推理”过程为例,我们“感知”世界的方式,总是通过非精确数据进行推理,从经验中学习,以及基于世界模型的尝试。就好比人类大脑辨认一只猫的过程,是基于经验的、常识模型的,而且是低精度的,我们不需要精确获知这只动物身上究竟有多少根毛发、眼睛尺寸的具体数值等,便可推理出这是一只猫。
今年的2019全球CEO峰会上,Graphcore CEO Nigel Toon在题为Exascale Compute with IPU的主题演讲中提到,如今智能机器(Intelligence Machine)的常规方案,即是获取训练(training)数据/传感器数据,然后借由“概率知识模型”在本地进行推理(inference),并最终得到结果。
“什么样的数据、什么样的方法去捕捉他们要训练的这些数据,数据间的应用关系;就像孩子一样,大脑不断地吸收他们的知识,才能产生这样的模型,这些是需要长时间建立的。”Toon表示。除此之外,这类型的工作极少出现分支和其他复杂行为任务(分支这类型的任务是CPU的专长),可以分解成单独、半独立的线程;而且计算精度要求并没有那么高。
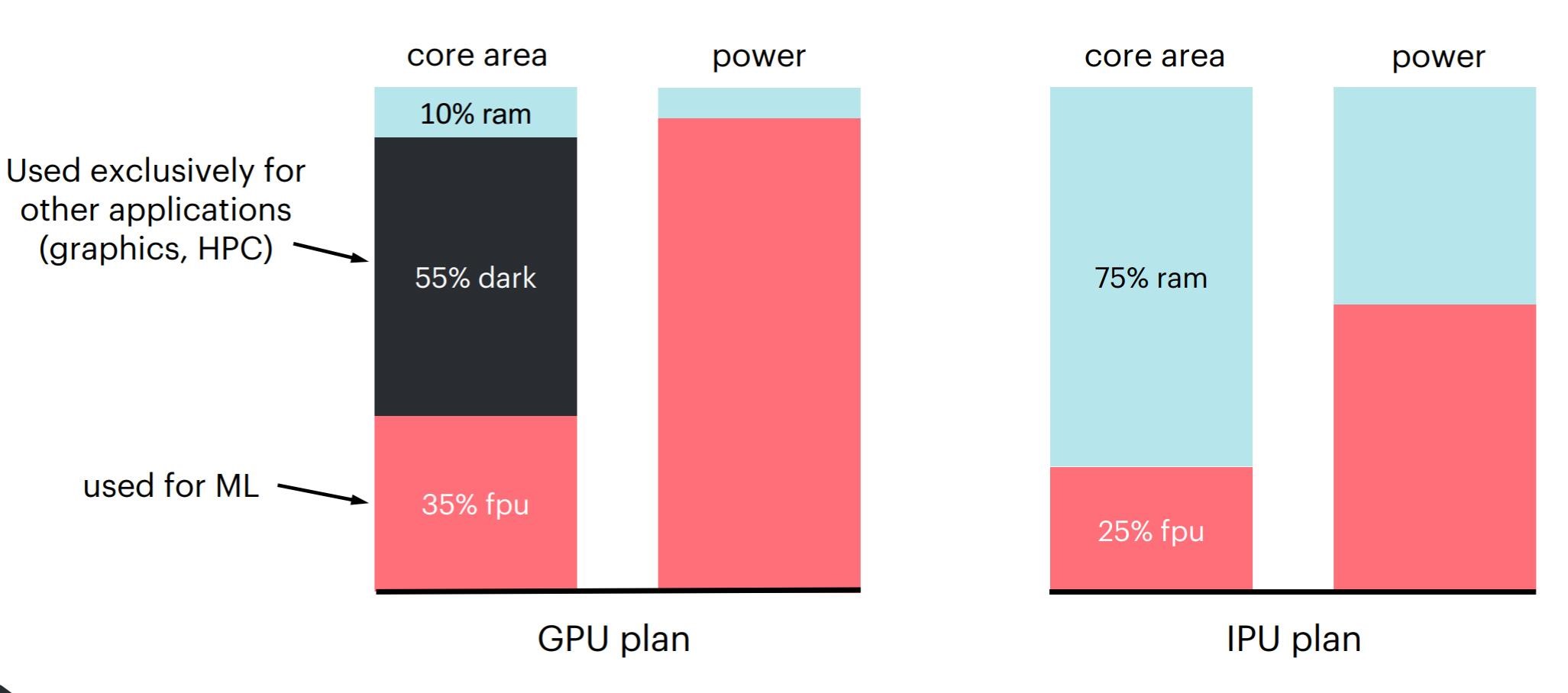
这样一来GPU这种具备处理重度并行任务能力的处理器也就非常适用,不过GPU的效率仍然不够高。Graphcore在前两年的一次主题演讲中特别提到了GPU的Dark Silicon[1],毕竟GPU有一部分是专为图形渲染做高性能计算的,这样一来就存在大量资源浪费;而且主流GPU核心区域的片上存储资源仍然是不够的,数据吞吐能力也就没有那么强。
前面提到的“知识模型”包含的特点有:自然呈现为计算图(graphs,代表的是知识模型和应用,所有机器学习模型都用graph的形式来表达)、支持高度并行计算、需要海量数据带宽、小型张量(small tensors)的低精度算法。这其实是AI芯片诞生的重要契机。
另一方面,“机器智能”的要求还在发生进化。我们现在更多的应用,并不是单纯能识别一只猫这么简单,更多的比如语言理解,以及更多的高级感知能力——如汽车辅助驾驶系统或者自动驾驶中,对司机情绪、疲劳程度的判断等。与此同时,模型尺寸正在变得越来越大。我们前两年还在说:好的卷积神经网络,通常是带有“上百万参数”和许多隐藏层的怪物。不过在这些年不同应用的发展中,“上百万”又算得上什么?
Toon列举在2016年1月的残差网络ResNet50参数总量25M,到2018年10月的BERT-Large自然语言模型发展到了330M,如今OpenAI会讲故事的文本生成模型GPT2——这是一个大型语言模型,具有15亿个参数;未来的新模型是朝着万亿(trillion)量级去的。
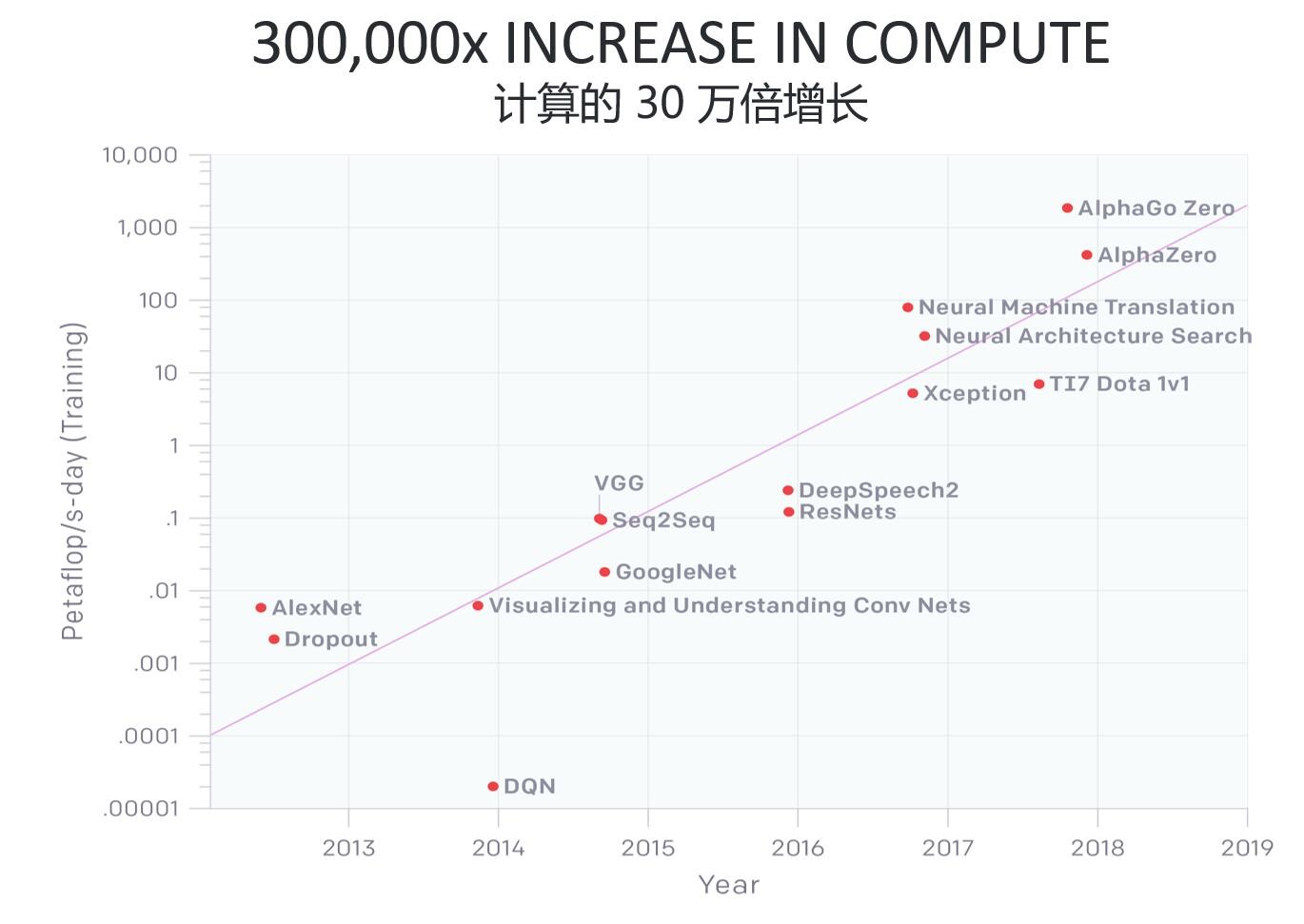
上面这张图,来自去年年中OpenAI发布的一份名为《AI与计算》的分析报告[2]。这份报告提到,自2012年以来,AI训练(training)任务应用的算力需求每3.5个月就会翻倍,这个数字可是超过了摩尔定律的;从2012年至今,AI算力增长超过30万倍。这张图纵轴的单位,每1个petaflop/s-day(pfs-day),就包含了一天每秒10^15次神经网络运行次数,或者总数大约10^20次操作(不过这个统计针对一次“操作”的定义,没有区分加法、乘法,而且不区分数据精度)。
需要注意的是,这张图的纵轴刻度并不呈线性,而是指数级增加。
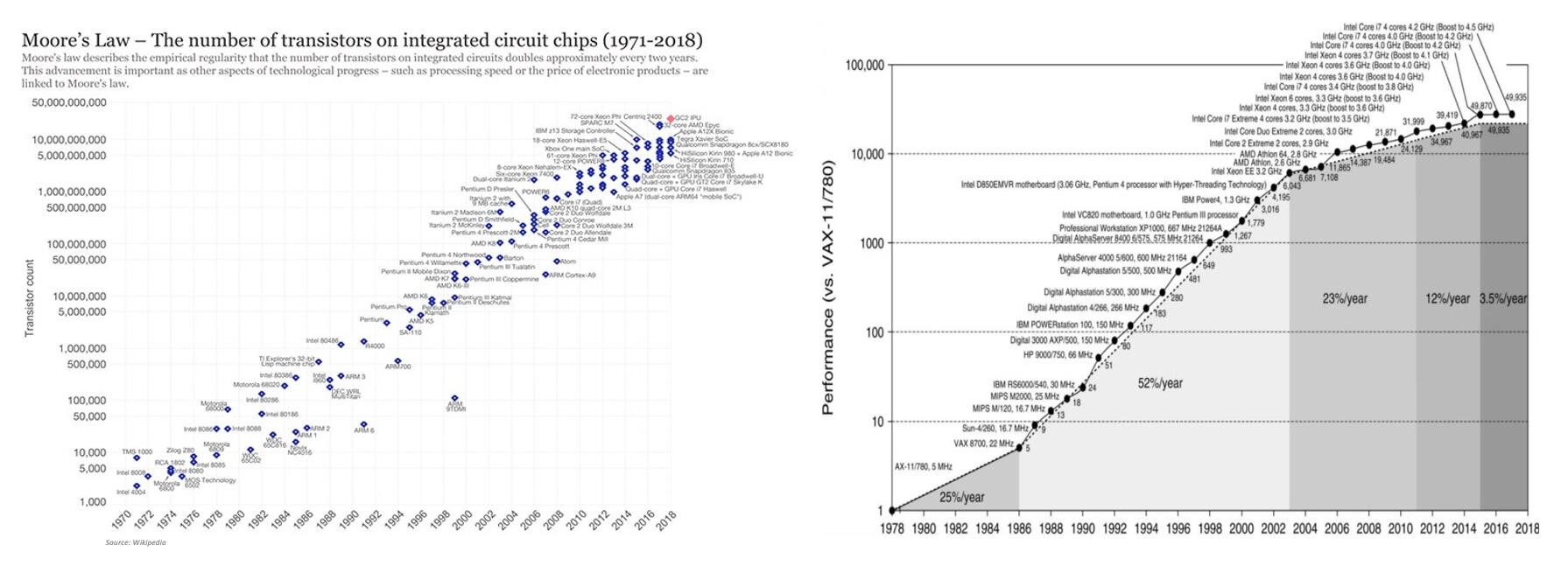
当我们真正去对比当前芯片的晶体管数量,以及性能变化时,其实很容易发现,摩尔定律大趋势是持续的,但登纳德缩放比例定律(晶体管密度增加同时,每个晶体管功耗会下降)已经达到极限——我们在先前的文章中也已经不止一次地提到过这个问题。早些年,Steve Scott还在英伟达特斯拉业务部门担任CTO(现在是Cray的CTO)的时候就说过这个观点:晶体管已经无法在体积缩小的情况下持续降低电压,这样一来,虽然集成的晶体管越来越多,但也意味着功耗越来越大:性能因此受到功耗限制,每一次制程迭代,都会加重该问题。
所以解决方案是?
去年《连线(WIRED)》杂志在采访AI之父Geoff Hinton说:“我认为我们需要转向不同类型的计算机。幸运的是我这里有一个...”Hinton从钱包里掏出一枚又大又亮的硅芯片:IPU。
这段是Toon在全球CEO峰会上讲的,看起来很像是个段子。不过从连线杂志的原报道来看[3],这件事竟然是真的,当时Hinton拿出来的是Graphcore的原型产品。Geoff Hinton现如今是谷歌AI顶级研究人员,此人早在上世纪70年代就开始构建人类大脑从视觉层面理解世界的数学模型。所以这件事,又让Graphcore获得了一重加持。
实际上,现如今的AI芯片已经遍地开花了,不管是训练(training)还是推理(inferencing),包括Arm前不久都已经发布了针对边缘AI推理的专用IP。这其实已经足够表明,这种“架构革命”风卷残云式的来袭。
简单地说:CPU通过手机数据块来处理问题,然后针对这些信息跑算法或执行逻辑操作,其通用性很好,适用于各种计算,但可并行的核心数量经常只有个位数;GPU核心数或执行单元数量大,可同时执行更多任务,但如前所述,其效率还是不够的;而AI芯片,则能够从不同位置同时拉来大量数据,进行快速和更高并行数的处理:Graphcore的IPU(Intelligence Processing Units)是其中一种。
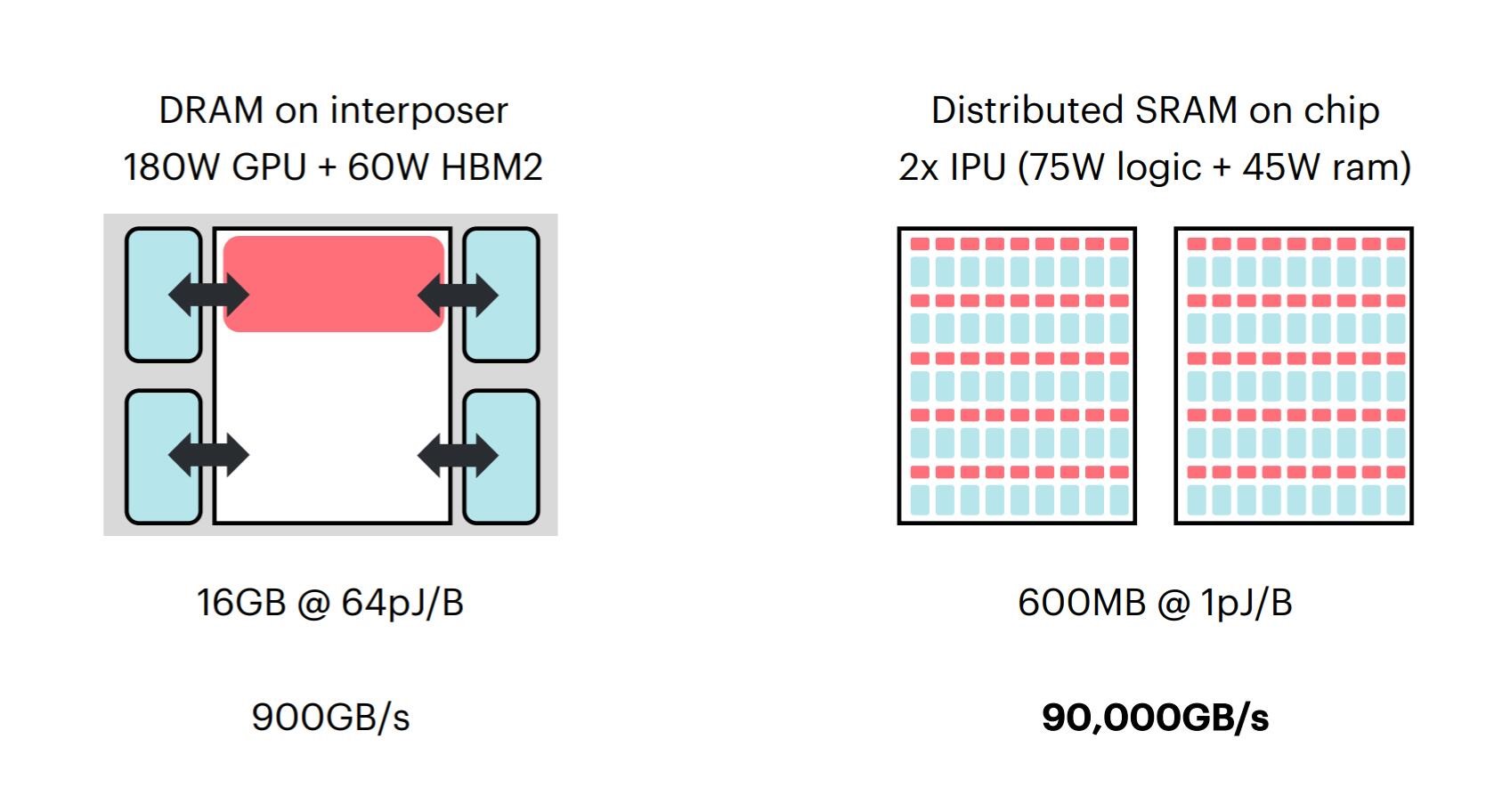
Graphcore可以认为是这个领域最早的一批开创者。IPU的“架构变革”部分体现在,整合芯片逻辑和存储部分,在片上分布SRAM,让IPU达到100倍吞吐;此外,16nm "Colossus" IPU包含了超过1200个低精度浮点运算核心,和所有机器学习所需的控制操作与超越函数,125 teraFLOPS算力;每个核心能够跑至多6个线程。
另外搭配Graphcore针对机器智能设计的软件工具链Poplar。Toon先前在接受采访时曾提到:“Poplar建立在计算图形抽象(computational graph abstraction)的基础上。其graph compiler的IR(intermediate representation中间层)是个大型的定向图。”Graph图像共享作为内部的representation,整个知识模型的representation最后都会分解为高度并行的工作负载,然后在IPU处理器之间进行调度和执行。一句话概括就是,Poplar通过不同层级的优化,在IPU核心之间部署任务。[4]
Poplar支持TensorFlow、PyTorch、OONX、Keras等框架。“从这些高层级的框架获取输出,喂进Poplar软件层,产生高层级的graph,并将这些graph映射到跑在IPU处理器上的一张完整计算graph上。”这其实也是当前AI芯片开发的常规思路。
总结一下,这些尝试解决的问题实质就是本文第一部分提出的,当代“知识模型”的那些要求,包括高吞吐、高度并行、低精度等,并在性能要求上满足模型越来越贪婪的需求。
IPU的几个特点,第一是被称作graphs型的计算(computation on graphs,包括了高度并行、稀疏化(sparse)、高维度模型、分布式片上存储);第二,低精度,宽动态范围算法(混合精度,16.32,和更低);第三,静态图形结构(编译器可分解任务、分配存储,调度messages,块同步并行、无序化、adress-less通讯);最后是Entropy Generative(比如产生统一分布整数、Generation of vectors of approximately Gaussian distributed floats等)。
ExaFLOPS级别的扩展
Nigel Toon提到,IPU产品已经向戴尔出货,戴尔易安信IPU服务器即是一款比较具体的产品。如我们先前所了解的那样,这款数据中心设备,每台插8张C2 PCIe加速卡(每个C2卡包含两个IPU),能够实现1.6 petaFLOPS的算力。戴尔其实也是Graphcore企业市场策略的重要组成部分。
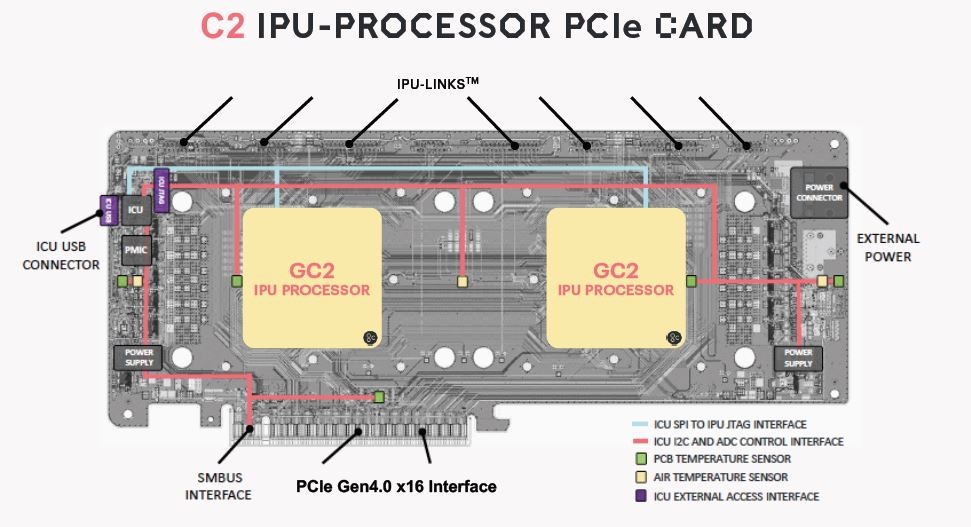
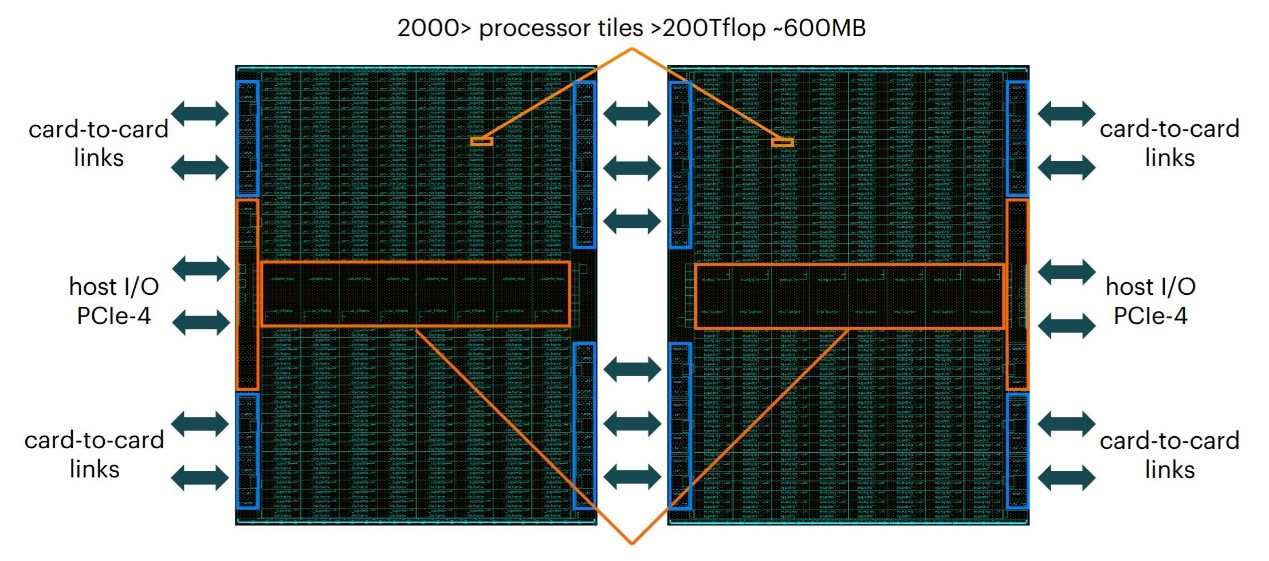
从IPU先前的介绍来看,它具备card-to-card links的弹性扩展机制。在前不久的NeurIPS展会上占了一个名为Rackscale IPU-POD的参考设计。Nigel Toon这次讲IPU-POD称作“机器智能超级计算机”,“这部分去年10月,我们开始逐步付诸实施。”这可以认为是将IPU弹性应用到极致的某种示例。
一个单独的42U机架IPU-Pod能够提供超过16 PetaFLOPS混合精度算力;一套32个IPU-POD(至多4096个IPU),可以将算力弹性扩展至超过0.5 ExaFLOPS的程度,这对同硬件的训练和推理,都是相当惊人的吞吐量。
显然针对Toon前面提到神经网络模型在体积和算力需求方面的扩张,是越来越必要的一种应用方案。

作为英国的一家独角兽企业,Graphcore是被Nigel Toon寄予了厚望的。他一直期望在英国建立一个具备Arm同等影响力的科技企业。当前Graphcore的融资总额已经达到3.25亿美元,这在我们先前的全球CEO峰会展望篇中已有所提及。不过在应对AI芯片越来越多市场参与者,包括大量初创型企业,以及Intel、英伟达这些老牌企业的入场,Graphcore和Nigel Toon的竞争压力显然也是不小的。

参考来源:
[2]https://openai.com/blog/ai-and-compute/
[3]https://www.wired.com/story/googles-ai-guru-computers-think-more-like-brains/
[4]https://www.eet-china.com/news/201909211859.html

