


2014年3月24日,GTC 2014在加州圣何塞举行,依旧是大家熟悉的“皮衣刀客”黄仁勋。
这场大会围绕着Tegra K1、Maxwell以及Pascal架构展开,汽车、智能、工业化成为了2014年的主题,还有让游戏玩家感到震撼的GTX Titan Z,这张怪兽般的显卡采用了双芯设计,内置两块GK110芯片,CUDA核心总数达到了惊人的5760个,规格相当于两张GTX Titan Black旗舰显卡。

总功耗达到375W的GTX Titan Z目标是提前让用户进入4K乃至5K时代,它的售价在当时来看也是傲视群雄:海外版售价2999美元,国行版本售价23999元,比起今天消费端旗舰显卡RTX 4090来说,也是有过之而无不及。
而在卡皇问鼎GPU性能之前,英伟达还低调地丢出一项技术,在当时并不为大众所知,而在2024年的今天,这项技术已经成为人工智能帝国的基石之一。
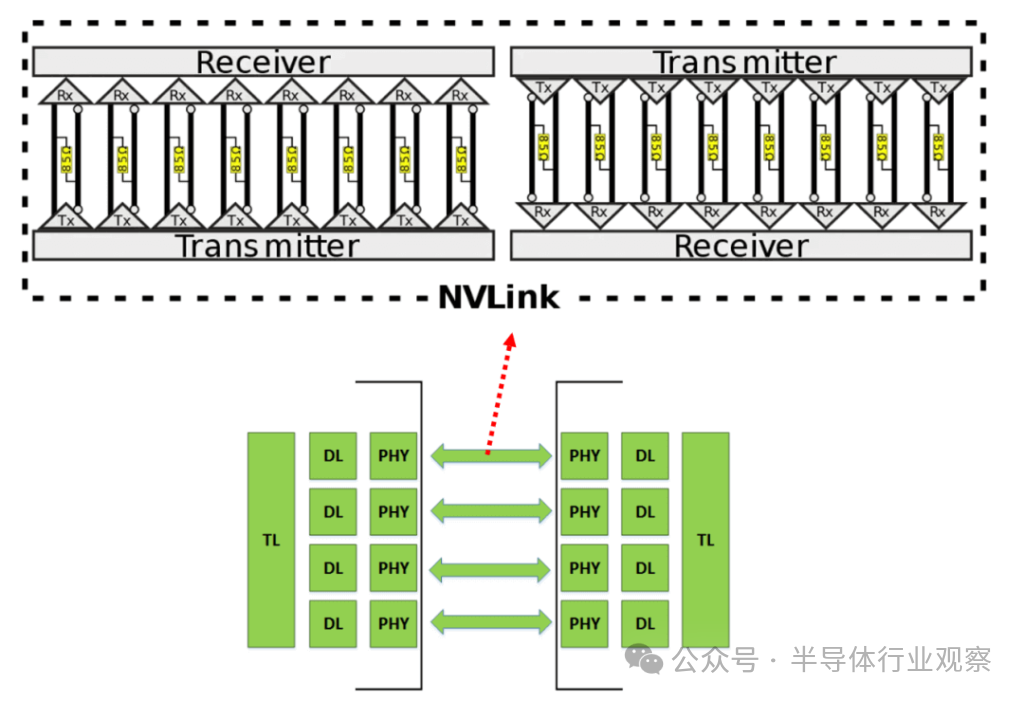
这项技术的名字,就是NVLink。
未来技术
在GTC 2014上,英伟达CEO黄仁勋如此形容大屏幕上显示的NVLink技术:它让 GPU 与 CPU 之间共享数据的速度快了5 - 12倍,这不仅是全球首例高速 GPU 互联技术,也为百亿亿次级计算铺平了道路。
这样的说法并非夸张,2014年时行业还在使用PCI Express 3.0,这项技术最初于2007年由PCI-SIG宣布,经过多次修改后才在2010 年 11 月正式推出,但放在当时来看,PCIe 3这项技术已经跟不上GPU算力的需求。英伟达在官方稿中提到,GPU 需要通过 PCI Express (PCIe) 接口连接至 x86 CPU,但这项技术生来就有的缺点,限制了 GPU 存取 CPU 系统内存的能力,对比CPU内存系统要慢4-5倍。
而隔壁的IBM为英伟达提供了一个契机,当时IBM POWER CPU 的带宽高于 x86 CPU,因此PCIe 成了更明显的瓶颈,英伟达正因为带宽不足而发愁,二者一拍即合,合作开发了第一代NVLink。官方宣称,NVLink 1.0接口可以和一般 CPU 内存系统的带宽相匹配,可以让 GPU 能够以全带宽的速度存取 CPU 内存,基本解决了此前的CPU和GPU互联的带宽问题。
从当时来看,与传统的PCIe 3.0相比,NVLink这一高带宽互联技术能大幅提高加速软件应用的性能,GPU 的显存速度快但容量小,CPU 内存速度慢但容量大。因为内存系统的差异,加速的计算应用一般先把数据从网络或磁盘移至 CPU 内存,然后再把数据复制到 GPU 显存,数据才可以被 GPU 处理。凭借 NVLink,数据在 CPU 内存与 GPU 显存之间的移动速度得到了大幅提升,从而让 GPU 加速的应用能够大幅提升运行速度。

而统一内存则是NVLink的另一大特性,它能简化 GPU 加速器的编程,让程序员能够将 CPU 内存和 GPU 显存视为一个内存块。程序员可以操作数据,无需担心数据存在于 CPU 内存还是 GPU 显存当中。英伟达官方表示,NVLink技术将被用于连接GPU与支持 NVLink 技术的 CPU,另外还将用于在多颗 GPU 之间直接提供高带宽连接。此外,尽管拥有极高的带宽,NVLink 却在每比特数据的传输上比 PCIe 节能得多。
英伟达为此还专门设计了一个模块来容纳 Pascal 架构的 GPU 与 NVLink,这一全新的 GPU 模块仅为当时标准 PCIe 显卡尺寸的三分之一,Pascal 模块底部的接口使其能够插入到主板当中,从而改善了系统设计、提升了信号完整性。
英伟达和IBM对这项技术可以说是非常看好,几个大佬轮番给它背书,虽然两家公司依旧是制定PCIe 标准的PCI-SIG成员之一,但NVLink所代表的技术野心已不言而喻。
NVIDIA GPU 工程高级副总裁 Brian Kelleher 表示: “NVLink 技术通过大幅提升 CPU 与 GPU 之间的数据传输速度,最大限度缩短了 GPU 等待数据处理的时间,从而释放了 GPU 的全部潜能。”
IBM 副总裁兼 IBM 院士 Bradley McCredie 表示: “NVLink 让 CPU 与 GPU 之间能够快速交换数据,从而提升了整个计算系统的数据吞吐量,克服了当今加速计算的一大瓶颈。NVLink 让开发者能够更轻松地修改高性能与数据分析应用,以便充分利用加速的 CPU-GPU 系统。我们认为,该技术标志着我们对 OpenPOWER 生态系统又做出了一大贡献。”
作为一项新兴技术,NVLink的应用比大家想象的要快得多,2014年年底,美国能源部 (DoE) 就宣布授予 IBM 和 NVIDIA 建造两台新的旗舰超级计算机,分别是橡树岭国家实验室的Summit系统和劳伦斯利弗莫尔国家实验室的Sierra系统,而NVLink就是其中的关键技术,英伟达的GPU 和 IBM POWER CPU 通过 NVLink 互连技术连接,为它们提供至少 100 petaflops 的计算性能。
而在英伟达后续发布的Tesla P100芯片上,就搭载了NVLink 1.0技术。如下图所示,两个 GPU 之间有 4 个 NVlink,每个链路包含 8 个通道,每个通道的速率为 20Gb/s。因此,整个系统的双向带宽为160GB/s,是PCIe3 x16的五倍。基于NVLink 1.0,可以形成四个GPU的平面网格结构,每对之间具有点对点连接,8 个 GPU 对应一个立方体网格,就可以组成一个 DGX-1。

比较有意思的是,2016年,英伟达CEO黄仁勋向当时还尚属稚嫩的 OpenAI 送了一份价值129000美元大礼——世界上第一台 DGX-1 超级计算机。
根据英伟达的表述,DGX-1拥有双Xeon处理器和8颗基于Pascal架构的Tesla P100 GPU加速器,整机拥有170 TeraFLOPs的半精度 (FP16) 峰值性能,还配备了512GB系统内存和128GB GPU内存,非常适合于深度学习领域。
这台超算成为了OpenAI推动AI技术发展的动力之一,在拥有DGX-1前,OpenAI技术人员一直受到系统计算能力的限制,而有了它之后呢?OpenAI 研究总监Ilya Sutskever 表示,DGX-1可以使每次实验所需的时间缩短数周,能使研究人员能够提出以前可能不切实际的新想法,解决了这家非盈利组织的算力焦虑。
而NVLink也正是在此时为大众所熟知,开始发挥它在深度学习中不可或缺的作用。
带宽为王
带宽究竟有多重要?它对于英伟达来说,是不亚于GPU本身的另一条生命线。
一般来说,传统冯诺依曼架构下的计算设备会存在几个瓶颈,计算墙、存储墙、通信墙等,其中,通信墙的问题是以AI为代表的分布式训练最为头疼的部分。
分布式训练中,各个GPU在机内和机间不断进行通信。服务器内部的显卡之间需要频繁进行信息的交换,服务器与服务器之间也需要大量的信息传递,如果采取并行策略,在模型或流水线并行的过程中,就需要通过通信来同步梯度并等待更新完成,这就引入了大量的机内和机间All-reduce操作,就会带来相当大的时间成本开销,这些都需要一套软硬件协调优化好的通信方案。
当然,不止是火热的AI,对于更大范围的HPC和数据中心来说,通信带宽一定程度上比单芯片算力更重要,大型集群中有着成百上千的芯片,要把它们拧在一起并不容易,规模越大的并行计算,就越渴求一套完整的解决方案。
让我们把目光放回到2014年,当时的英特尔就是该领域的最强者,拥有完整的独立CPU以及CPU+GPU异构架构解决方案的它,只需要做好运算效率的提升以及编程环境的改善,甚至不用对PCIe做出革命性的改动,就能轻松拿下绝大部分市场。
英伟达就不一样了,做游戏GPU起家的它摸到了行业的天花板,必须寻新的增量,拿ARM授权做移动处理器是一方面,前景广阔的数据中心它也不想错过,但它的缺点很明显,就是没有一套作为HPC基础的通用处理器节点解决方案,PCIe总线带宽更是牢牢拖着了它前进的步伐。
而IBM此时抛出橄榄枝,虽说是出于它在高性能计算市场中败退的原因,但对于英伟达来说,无疑是下了一场及时雨,两家合作颇有些蜀吴联合抗击魏国的意味。
有了IBM的部分HPC技术,英伟达如鱼得水,在NVLink 1.0的底子上继续发展,伴随着P100、V100、A100、H100等计算卡的推出,NVLink迎来了自己的高速发展。

2017年,Nvidia推出了第二代NVLink技术。它将两个 GPU V100 芯片与六个 NVLink 连接,每个 NVLink 包含八个通道。每个通道的速率增强至25Gb/s,系统双向带宽达到300GB/s,几乎是NVLink 1.0的两倍。同时,为了实现八个GPU之间的全对全互连,Nvidia引入了NVSwitch技术。NVSwitch 1.0有18个端口,每个端口带宽为50GB/s,总带宽为900GB/s。每个NVSwitch保留两个端口用于连接CPU。使用6个NVSwitch,可以建立8个GPU V100芯片的全对全连接。
2020年,NVLink 3.0技术出现。它通过 12 个 NVLink 连接两个 GPU A100 芯片,每个 NVLink 包含四个通道。每个lane的速度为50Gb/s,系统的双向带宽达到600GB/s,是NVLink 2.0的两倍。随着NVLink数量的增加,NVSwitch上的端口数量也增加到36个,每个端口的速率为50GB/s。DGX A100由八个GPU A100芯片和四个NVSwitch组成,如下图所示。
2022年,NVLink技术升级到第四代,允许两个GPU H100芯片通过18条NVLink链路互连,每个链路包含2个lane,每个lane支持100Gb/s PAM4的速率,从而双向总带宽增加到900GB /s。NVSwitch也升级到了第三代,每个NVSwitch支持64个端口,每个端口速率为50GB/s。DGX H100由8颗H100芯片和4颗NVSwitch芯片组成。
2024年,NVLink第五代与Blackwell一同推出,它大幅提高了大型多 GPU 系统的可扩展性。单个英伟达Blackwell Tensor Core GPU可支持多达18个NVLink 100千兆字节/秒(GB/s)连接,总带宽达到1.8兆字节/秒(TB/s),是上一代产品的2倍,是PCIe Gen5带宽的14倍以上。而新机架Nvidia GB200 NVL72 也引入了第五代 NVLink,它在单个 NVLink 域中连接多达 576 个 GPU,总带宽超过 1 PB/s,高速内存高达 240 TB。
从单通道速率来看,NVLink一般是同期PCIe的两倍左右,而总带宽的优势则更加明显,NVLink约为PCIe总带宽的五倍,在带宽上可谓是遥遥领先。
值得一提的是,在第四代NVLink发布时,英伟达正式将其称为NVLink-C2C ,此时NVLink已经升级为板级互连技术,它能够在单个封装中将两个处理器连接成一块超级芯片。比如它通过连接两块 CPU 芯片,使 NVIDIA Grace CPU 超级芯片具有 144 个 Arm Neoverse V2 核心,为云、企业和 HPC 用户带来了高能效性能;NVLink-C2C 还将 Grace CPU 和 Hopper GPU 连接成 Grace Hopper 超级芯片,将用于处理最棘手的 HPC 和 AI 工作的加速计算能力集合到一块芯片中。
英伟达表示,2023年计划在瑞士国家计算中心投入使用的 AI 超级计算机 Alps 是首批使用 Grace Hopper 的计算机之一,这套高性能系统用于处理从天体物理学到量子化学等领域的大型科学问题。
NVLink经过近十年的发展,解决了多个GPU芯片之间高带宽、低延迟的数据互连问题,已经成为英伟达GPU芯片的核心技术,也是其生态系统的重要组成部分,冲上2亿美元高峰的功劳,多多少少也要算它一份。
写在最后
事到如今,英伟达逢AI必提及算力,逢算力必提带宽,某种程度上也证明了这两者对于英伟达业务以及如今AI领域的影响。
我们从第一代DGX超算可以看出来,英伟达的野心就不是卖卖显卡而已,它要做的是卖解决方案,卖自己的独家技术,而对于这套方案,英伟达早已经打好了腹稿:先解决带宽通信,后解决通用处理器,最终登上新王座。
第五代NVLink配合全新的Blackwell,成为了2024年数据中心市场绕不过去的话题,而2014年NVLink初登场时,又有多少人能读懂英伟达当时的草蛇灰线呢?
