


本系列到此结束,一共7篇,8个小章节,再次感谢西安电子科技大学锤王的投稿。
Part8RIFFA驱动分析
18.1 RIFFA驱动文件构成
RIFFA的Linux驱动文件夹下有6个C源码文件,riffa_driver.c、riffa_driver.h、circ_queue.c、circ_queue.h、riffa.c、riffa.h。
其中riffa.c和riffa.h不属于驱动源码,它们是系统函数调用驱动封装的一层接口,属于用户应用程序的一部分。
circ_queue.c和circ_queue.h是为在内核中使用而编写的消息队列,用于同步中断和进程;riffa_driver.c和riffa_driver.h是驱动程序的主体。
注意:RIFFA驱动全程采用面向对象的编程思想。
28.2 RIFFA驱动的消息队列
消息队列是一种线程间同步的方法,在Linux应用编程中又称为无名管道,其主体就是一个FIFO,读写跨接在两个线程间。
消息队列主要是用来同步并且传递数据,所以都有阻塞功能,但因为RIFFA中用的是自己编写的消息队列不自带阻塞,故需要配合阻塞I/O实现完整的消息队列功能。
消息队列的操作函数和数据结构在circ_queue.c与circ_queue.h中,下面看一下这两个文件。
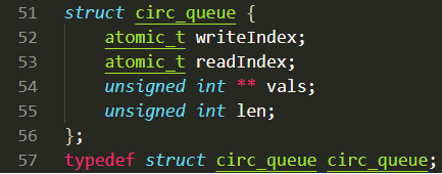
circ_queue.h中定义了消息队列的数据结构circ_queue,里面的成员中,writeIndex和readIndex是写指针和读指针,类型是原子变量,为了解决多线程操作时的竞争问题;**vals是指针数组,指向消息队列的存储体;len是消息队列长度。
circ_queue.c中定义了消息队列的初始化函数init_circ_queue,如下所示:
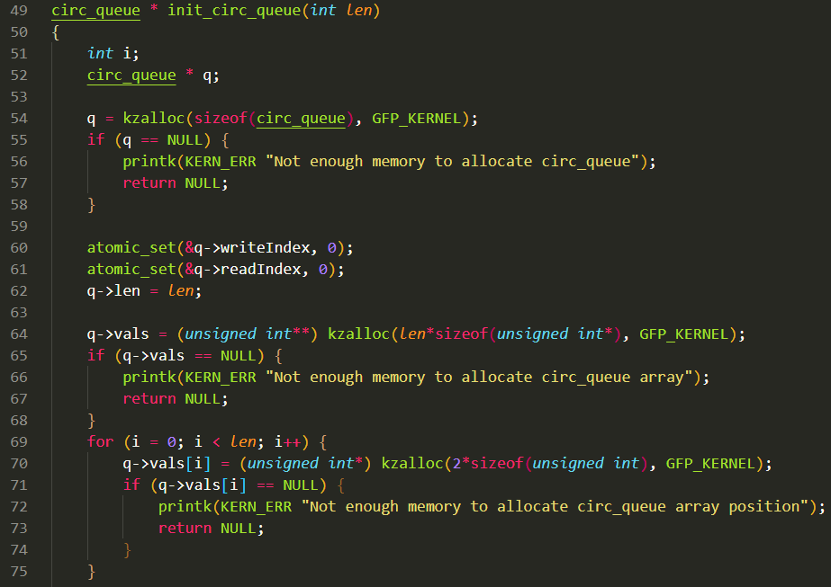
首先调用kzalloc创建了circ_queue结构体指针q,这个q就是描述消息队列的对象,然后把读写指针复位,接着又调用kzalloc分配了消息队列存储体的数组整体,每个元素都是一个空指针(此时消息队列还没有生成),最后为每一个空指针都分配两个数据空间,此时消息队列建立完毕,q中所描述的是一个二维数组,行数为len,列数为2,也就是一个存储单元能存2个数。
不过这还不是消息队列的全貌,再来看一个函数queue_count_to_index,这个函数是用来将读写指针变成数组的索引号的:

可以看到这个函数对count参数(传进来的读/写指针)做了模运算,说明这是一个环形队列。消息队列的全貌如下图示意:
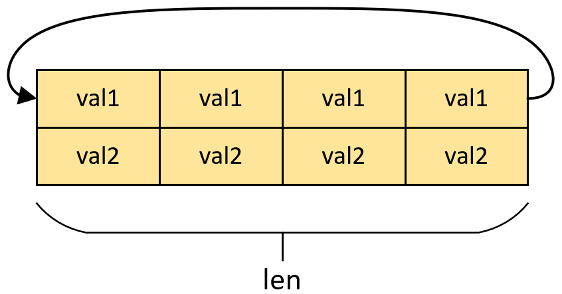
读写消息队列函数就没什么好说的了,就是对这个环形缓冲区进行一次读写,每个单元存两个值,成功返回0,失败返回1。值得注意的是,和FIFO一样,读数据不会让数据消失,只是读写指针自增了而已。
写消息队列函数为push_circ_queue;读消息队列函数为pop_circ_queue。
38.3 RIFFA驱动创建字符设备
剩下的驱动源码都在riffa.c和riffa.h中了,下面先看创建字符设备。创建字符设备在模块插入函数中进行,即fpga_init。
首先将原子操作数used_fpgas[]初始化,used_fpgas是一个数组,里面标记了有几个FPGA在用这个驱动。
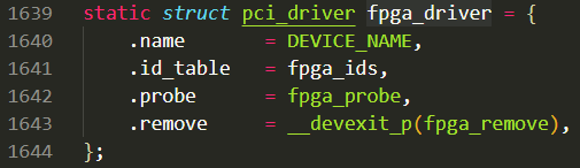
然后调用pci_register_driver函数将pci_driver结构体注册到PCI总线上,pci_driver如下所示,定义了PCI设备名、ID列表、probe/remove函数。
然后调用register_chrdev函数,用自行分配好的主设备号、设备名和字符设备操作函数结构体去注册字符设备,字符设备操作函数结构体如下所示,可见里面只用到了ioctl接口。

最后就是调用class_create创建类,调用device_create在类下创建设备节点了,这些都是框架内的步骤。
48.4 RIFFA驱动初始化收发通道
RIFFA最多支持12个通道,函数allocate_chnls中初始化了这些通道。
RIFFA中用chnl_dir结构体描述一个通道的特征,如下所示:
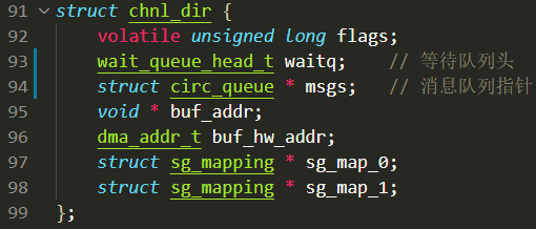
其中包括等待队列、SG链表存放的虚拟地址和总线地址和SG缓冲区的信息。
RIFFA中用fpga_state结构体描述一个运行着RIFFA的FPGA板卡的信息,如下所示:
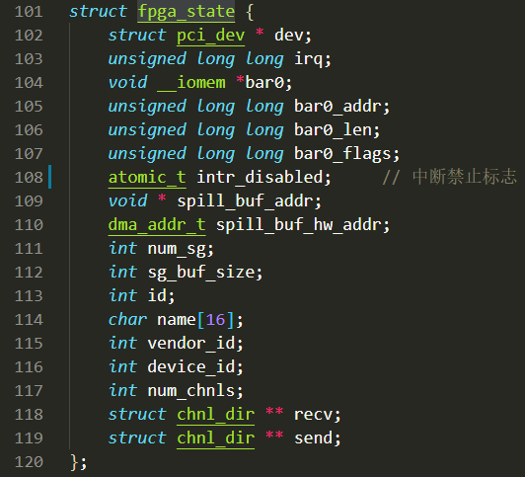
其中包括pci_dev结构体、中断号、BAR0空间虚拟首地址、BAR寄存器内容、页面、SG缓冲区、PCI设备ID号、实际通道数、收发通道等信息,其中收发通道就是两个chnl_dir结构体指针数组,数组元素指向对应通道的结构体对象。
介绍完这些结构体就可以开始看通道初始化代码了。收通道和发通道初始化完全一致,这里只看收通道吧。
首先调用kzalloc为每个收通道的chnl_dir结构体分配空间;然后调用init_waitqueue_head函数初始化每个收通道中的等待队列头;然后调用8.2小节的init_circ_queue函数为每个收通道都初始化一个消息队列,长度为5;最后调用pci_alloc_consistent函数建立一致性DMA,用于SG链表的存放,然后把返回的虚拟地址赋给chnl_dir结构体中的buf_addr、总线地址赋给buf_hw_addr,此处说明了RIFFA中每个通道都有自己的SG链表,是独立的。
此函数返回值为初始化成功的通道数。
58.5 RIFFA驱动的probe函数
先介绍一下RIFFA驱动的读写BAR0空间寄存器的函数read_reg和write_reg。read_reg函数中调用了Linux的API readl函数,readl是对虚拟地址读写的专用函数,位宽32位,同理,write_reg中调用的writel也是。从代码中可以看出,read_reg和write_reg其实就是从BAR0空间起始地址开始按偏移去读写寄存器。当然,Xilinx的PCIe IP核的用户侧地址也是减去BAR0首地址后剩下的偏移。这样用户就无需知晓BAR空间首地址了。
RIFFA的probe函数是fpga_probe。
probe函数首先调用pci_enable_device函数激活PCI设备;然后调用pci_set_master函数设置设备具有获得总线的能力,即调用这个函数,使设备具备申请使用PCI总线的能力;
然后调用pci_set_dma_mask辅助函数,检查PCI总线是否有处理64位地址的能力,宏DMA_BIT_MASK就是填写总线位数的,若有能力则调用pci_set_consistent_dma_mask函数协调总线为64位地址;
然后调用kzalloc为fpga_state结构体分配空间;然后就是分配并映射BAR0空间了,调用pci_request_regions函数向内存申请出映射BAR0空间的那片地方,然后调用pci_resource系列函数读出BAR0空间的起始物理地址和长度信息,然后用ioremap将BAR0映射的物理地址转换为虚拟地址,并将首地址赋给fpga_state结构体中的bar0;
然后进行中断申请,调用pci_enable_msi初始化MSI中断结构、分配MSI中断号并覆盖掉dev中原来的INTx中断号,然后再调用request_irq函数申请MSI中断并注册中断回调函数,回调函数为intrpt_handler;
然后就是调用pcie_capability_read_dword和pcie_capability_write_dword函数设置、读取配置空间中的一些内容,如RCB;
然后调用read_reg函数读取BAR0空间中的INFO_REG_OFF寄存器信息,依此设置实际通道号、存储SG链表的空间的大小、最大SG缓存块个数,然后依据这个寄存器中的信息判断FPGA中的配置是否是驱动支持的。
然后调用上一节的allocate_chnls函数初始化收发通道,并判断是否所有该初始化的通道都初始化成功了。
然后调用pci_alloc_consistent再创建一个一致性DMA映射空间,物理地址给spill_buf_hw_addr,虚拟地址给spill_buf_addr,这段缓冲区是用来收集接收SG缓冲区溢出的数据的,但是这片缓冲区用户空间无法访问,相当于就是个垃圾堆作用就是让FPGA端发送完他想发的数据,但是溢出的这部分数据不能被访问。
68.6 RIFFA驱动的中断回调函数
中断回调函数就是前面用request_irq注册的intrpt_handler函数。
进入中断回调函数后如果禁止中断标志位没置位的话就先读取vect0寄存器获得中断原因,若通道数大于6那再把vect1也读了。然后调用process_intr_vector函数,下面主要说明process_intr_vector函数。
process_intr_vector函数中进行的是中断的上半部处理,将vect寄存器中的值传入该函数后依照各bit位判断出中断原因,分出5种中断:Tx数据开始中断、Tx SG读完成中断、Tx数据完成中断、Rx SG读完成中断和Rx数据读完成中断。
若执行Tx数据开始中断,则先读取TX_OFFLAST_REG_OFF寄存器和TX_LEN_REG_OFF寄存器以获取offset和FPGA想要发送的长度,然后将这两个参数分两次推入消息队列,因为消息队列一个单元有两个数据,所以每次消息队列传递的除了数据本身还有消息类型,这两次的消息类型分别为EVENT_TXN_OFFLAST和EVENT_TXN_LEN。
若执行Tx SG读完成中断,则消息类型发送EVENT_SG_BUF_READ,数据填0,其实是没用的数据。
若执行Tx数据完成中断,则从TX_TNFR_LEN_REG_OFF寄存器中读取FPGA实际发送的长度,然后推入消息队列。
若执行Rx SG读完成中断,则消息类型发送EVENT_SG_BUF_READ,数据也是没用的数据。
若执行Rx数据读完成中断,则从RX_TNFR_LEN_REG_OFF寄存器中获取实际传输的长度,然后推入消息队列。
处理完中断后调用wake_up函数唤醒主进程,让主进程处理中断下半部,中断回调函数返回IRQ_HANDLED,表示中断处理完成。
78.7 RIFFA驱动建立SG缓冲区
RIFFA驱动中定义了sg_mapping结构体来存放描述SG缓冲区的相关成员,定义如下:
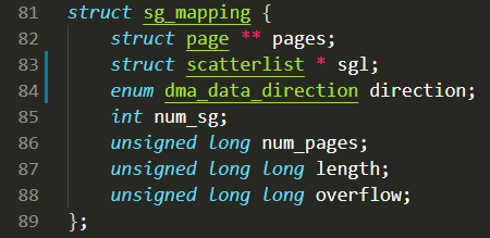
num_sg存放了实际分配的SG缓存块个数;num_pages记录了SG缓冲区实际占用的页数;overflow存放了实际溢出大小。
RIFFA中创建SG缓冲区的函数是fill_sg_buf,返回一个sg_mapping结构体指针。
首先为sg_mapping结构体对象分配空间;
然后计算SG缓冲区需要占用内存的页数(按页对齐),需要注意的是,参数udata是用户空间传进来的缓冲区虚拟首地址强制转换成64位无符号整形了,所以它现在代表SG缓冲区的虚拟首地址。
然后调用kmalloc建立page结构体指针数组,此时数组元素均为空指针,然后调用get_user_pages函数锁定SG缓冲区的物理页防止被换出到硬盘中,并把page数组中的指针元素指向SG缓冲区的物理页。Linux推荐用读操作信号量down_read和up_read保护get_user_pages函数。这个信号量是current->mm->mmap_sem,current是当前进程、mm是当前进程中的虚拟内存空间、mmap_sem是这里面的读写信号量。
然后创建scatterlist数组并调用sg_init_table函数初始化数组,然后循环地调用sg_set_page函数填充sglist数组的每个元素(页面、偏移、长度)。变量fp_offset是第一个sg块相对于该页起始地址的偏移量,只有第一次填充时fp_offset可能不为0,其他时间必为0(即按页对齐)。
然后调用dma_map_sg函数建立SG映射,从此udata表示的这片缓冲区就是SG缓冲区了。
然后遍历scatterlist数组中的各个scatterlist结构体变量,用sg_dma_address函数获取各个SG缓存块的总线起始地址、用sg_dma_len函数获取各个SG缓存块的长度。
然后将获得的各个SG缓存块总线首地址和长度按序填充到传入本函数的sg_buf_ptr数组中(每个元素32位无符号整形),如下所示:
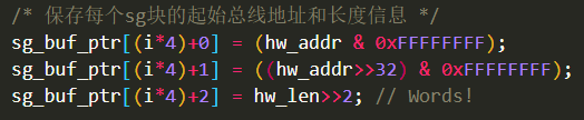
第一行是SG缓存块的总线首地址低32位、第二行是高32位、第三行是SG缓存块长度(单位DW)。这三行代码构成的就是一个描述符,共96bit(总共128bit,有效是96bit)。你可能会问了,这个sg_buf_ptr数组是什么?其实它就是前面初始化收发通道时在allocate_chnls函数中建立的一致性DMA缓冲区的虚拟首地址。
如果数据溢出,即FPGA要传的数据量大于SG缓冲区的容量,则还需构造访问公共缓冲区(存放溢出数据)的描述符,只不过描述符里的物理地址不是SG缓冲区的了,而是在allocate_chnls函数中为溢出建立的一致性DMA spill。
88.8 RIFFA驱动读通道函数
函数chnl_recv用于将FPGA发送的数据读到缓冲区内。
首先调用宏DEFINE_WAIT初始化等待队列项;然后把传入的参数timeout换算成毫秒,这个时间是最长阻塞时间。
函数主体是一个while(1)大循环,只有当处理完Tx数据完成中断或出错时函数才会返回。在每一轮执行中,首先执行内嵌的小while,在小while中首先读取对应通道上的recv消息队列,若返回值为0说明成功出队,小while运行一遍后就会执行下面的代码;若返回值为1说明队列可能是空的,也就是还没有中断到来,此时调用prepare_to_wait函数将本进程添加到等待队列里,然后执行schedule_timeout休眠该进程(有阻塞时间限制),此时在用户看来表现为ioctl函数阻塞等待,但中断还能在后台运行(中断也是一个进程)。
若此时驱动接收到一个该通道的Tx中断,那么在中断回调函数里将中断信息推入消息队列后就会唤醒chnl_recv所在的进程。进程唤醒后调用finish_wait函数将本进程pop出等待队列并用signal_pending查看是否因信号而被唤醒,如果是 需要返回给用户并让其再次重试。如果不是被信号唤醒,则再去读一下消息队列,此时会将消息类型存入msg_type,消息存入msg中,然后退出小while。
接下来进入一个switch语句,这个switch是根据msg_type消息类型选择处理动作的,即中断处理的下半部。
若消息类型是EVENT_TXN_OFFLAST,说明offset从中断回调函数中传过来了,则保存这个变量。
若消息类型是EVENT_TXN_LEN,说明FPGA要发送的长度len(DW)传过来了,并将长度左移2位转成Byte并保存。然后检查地址是否溢出了,一般不会溢出,除非缓冲区虚拟地址地址太高了;然后检查FPGA要传的数据是否超出缓冲区范围了,如果超出了则将超出的部分的长度记录在变量overflow中;然后调用上小节的fill_sg_buf函数申请SG缓冲区,并更新未进行SGDMA映射的缓冲区首地址、剩余长度和剩余溢出数据量,最后调用write_reg通过PIO方式将SG链表所在的总线地址和长度告诉FPGA(长度是4*sg_map->num_sg,说明描述符其实总共128bit,但有效是96bit)。
接下来FPGA会用一致性DMA的方式读走SG链表并发送一个Tx SG链表读完成中断,也就是EVENT_SG_BUF_READ消息类型,在这里如果剩余长度大于0或者剩余溢出值大于0时就会重新执行上一段讲述的过程,即从上一次分配的结尾处再分配SG缓冲区,并发送SG链表给FPGA等等,不过一般不会发送这种情况,除非分配页时的get_user_pages函数锁定物理页出现了问题,少分了页才会出现这样的现象。
然后FPGA就会按SG链表一个一个SG缓存块的进行流式DMA传输,传输完毕后FPGA发送一个Tx数据读完成中断,即EVENT_TXN_DONE消息类型。这里比较好处理,调用dma_unmap_sg取消内存空间的SGDMA映射,然后释放掉页。
真正的读通道函数是chnl_recv_wrapcheck,chnl_recv只是它调用的,chnl_recv_wrapcheck函数的前面主要完成检查缓冲区地址是否DW对齐、通道号是否符合规定(chnl∈[0,12]),值得一提的是本函数中调用了test_and_set_bit函数,这个函数的意义是将chnl_dir结构体对象recv[chnl]中的flags置1并返回flags原来的置,这个操作的目的是防止有多个线程对同一个通道进行操作。多个线程可以操作不同的通道,但万不能操作同一通道,这样不仅没意义还容易产生竞态问题。参数确认成功后调用chnl_recv,接收结束后调用clear_bit函数把flags清零以便下次访问。
98.9 RIFFA驱动写通道函数
函数chnl_send用于将缓冲区内的数据发给FPGA,这个处理过程和chnl_recv基本一致。不一样的地方就是send是驱动主动发起的,所以没有开始中断,中断就两个:Rx SG链表读完成中断和Rx数据读完成中断。
另外,send之前,驱动调用write_reg函数通知FPGA本次PC将发送的真实数据量和offset/last。
真正的写通道函数是chnl_send_wrapcheck,chnl_send是它调用的,此函数内也进行了与上一小节chnl_recv_wrapcheck函数中相同的检查。
108.10 RIFFA驱动ioctl函数
RIFFA驱动程序中的ioctl接口是fpga_ioctl函数。参数如下所示:

ioctlnum是操作类型,ioctlparam是用户空间传入的数据,用copy_from_user拷贝到内核空间然后再执行相应的操作。
