

我是 雪天鱼,一名FPGA爱好者,研究方向是FPGA架构探索和数字IC设计。
关注公众号【集成电路设计教程】,获取更多学习资料,并拉你进“IC设计交流群”。
一、量化算法
1.1 K-Means
将一堆二维样本表示在坐标轴上,如下图左图所示:
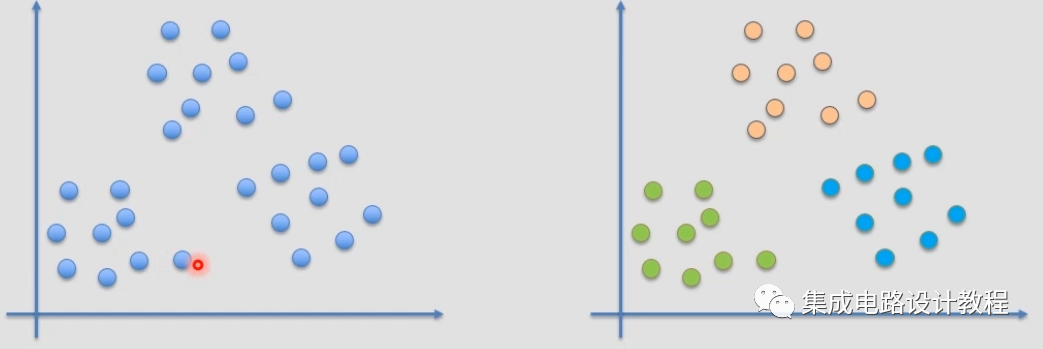
若我们将其用K-Means分为3类,如上图右侧所示,分为了绿、蓝和橙三类,还会告诉我们每类的聚类中心在哪里,这样就可以用三个数据去代替之前的多个数据,达到减少存储数据所需的内存空间大小的目的。对于一维数据而言,也是一样的,会将每个数据划分到具体的类(即 label),然后也告诉我们每个类的聚类中心(center)。

二、算法代码实现
1.1 K-Means代码实现
1 安装包
pip install scikit-learn2 导入 K-Means
from sklearn.cluster import KMeans3. 完整代码实现
def k_means_cpu(weight, n_clusters, init='k-means++', max_iter=50):
# flatten the weight for computing k-means,转为一维数据
org_shape = weight.shape
weight = weight.reshape(-1, 1)
# 若类别大于矩阵权重个数,则修改类别个数为矩阵权重个数。
if n_clusters > weight.numel():
n_clusters = weight.numel()
# 处理数据,进行分类
k_means = KMeans(n_clusters=n_clusters, init=init, n_init=1, max_iter=max_iter)
k_means.fit(weight)
# 读取 “聚类中心” 和 “labels”
centroids = k_means.cluster_centers_
labels = k_means.labels_
# 将 labels 还原为输入权重矩阵的形式
labels = labels.reshape(org_shape)
return torch.from_numpy(centroids).cuda().view(1, -1), torch.from_numpy(labels).int().cuda()函数 k_means_cpu:
weight:权重参数矩阵,tensor 数据类型。
n_clusters:将数据分为 n 类
return:返回两个参数,聚类中心 和 对应的 label 矩阵。
测试:
print("="*10)
print("未分类前的权重矩阵")
w = torch.rand(4, 5)
print(w,w.shape)
# print("展开")
# w2 = w.reshape(-1, 1)
# print(w2,w2.shape)
# num = w2.numel()
# print(num,type(num))
print("="*10)
print("经 K-Means 算法分类后的权重矩阵")
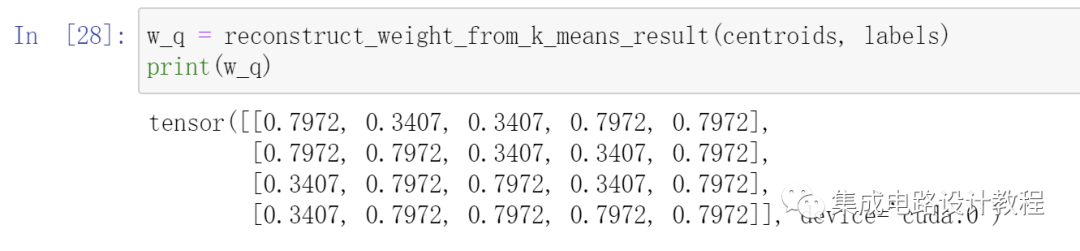
centroids, labels = k_means_cpu(w, 2)
print(centroids)
print(labels)输出结果:

可以看到这里将其分为了2类,首先输出 聚类中心,这里为 tensor([[0.7972, 0.3407]]),再输出labels矩阵。可以看到大点的权重都划分到了0.7972这一类,小点的权重都划分到了 0.3407这一类。复原即为:
下一节将讲述如何在实际网络中量化权重参数。

