

在人际交往中,言语是最自然并且最直接的方式之一。随着技术的进步,越来越多的人们也期望计算机能够具备与人进行言语沟通的能力,因此,语音识别这一技术也越来越受到关注。尤其,随着深度学习技术应用在语音识别技术中,使得语音识别的性能得到了显著提升,也使得语音识别技术的普及成为了现实。
语音识别技术
自动语音识别技术,简单来说其实就是利用计算机将语音信号自动转换为文本的一项技术。这项技术同时也是机器理解人类言语的第一个也是很重要的一个过程。
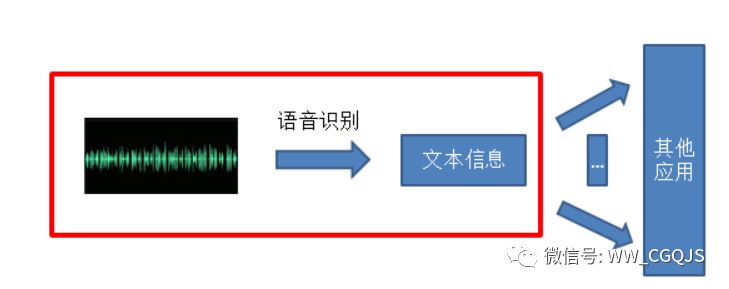
语音识别是一门交叉学科,所涉及的领域有信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等,甚至还涉及到人的体态语言(如人民在说话时的表情手势等行为动作可帮助对方理解)。其应用领域也非常广,例如相对于键盘输入方法的语音输入系统、可用于工业控制的语音控制系统及服务领域的智能对话查询系统,在信息高度化的今天,语音识别技术及其应用已成为信息社会不可或缺的重要组成部分。
语音识别技术的发展历史
语音识别技术的研究开始二十世纪50年代。1952年,AT&Tbell实验室的Davis等人成功研制出了世界上第一个能识别十个英文数字发音的实验系统:Audry系统。
60年代计算机的应用推动了语音识别技术的发展,提出两大重要研究成果:动态规划(Dynamic Planning, DP)和线性预测分析(LinearPredict, LP),其中后者较好的解决了语音信号产生模型的问题,对语音识别技术的发展产生了深远影响。
70年代,语音识别领域取得突破性进展。线性预测编码技术(Linear Predict Coding, LPC)被Itakura成功应用于语音识别;Sakoe和Chiba将动态规划的思想应用到语音识别并提出动态时间规整算法,有效的解决了语音信号的特征提取和不等长语音匹配问题;同时提出了矢量量化(VQ)和隐马尔可夫模型(HMM)理论。在同一时期,统计方法开始被用来解决语音识别的关键问题,这为接下来的非特定人大词汇量连续语音识别技术走向成熟奠定了重要的基础。
80年代,连续语音识别成为语音识别的研究重点之一。Meyers和Rabiner研究出多级动态规划语音识别算法(Level Building,LB)这一连续语音识别算法。80年代另一个重要的发展是概率统计方法成为语音识别研究方法的主流,其显著特征是HMM模型在语音识别中的成功应用。1988年,美国卡内基-梅隆大学(CMU)用VQ/HMM方法实现了997词的非特定人连续语音识别系统SPHINX。在这一时期,人工神经网络在语音识别中也得到成功应用。
进入90年代后,随着多媒体时代的来临,迫切要求语音识别系统从实验走向实用,许多发达国家如美国、日本、韩国以及IBM、Apple、AT&T、NTT等著名公司都为语音识别系统实用化的开发研究投以巨资。最具代表性的是IBM的ViaVoice和Dragon公司的Dragon Dectate系统。这些系统具有说话人自适应能力,新用户不需要对全部词汇进行训练便可在使用中不断提高识别率。
当前,美国在非特定人大词汇表连续语音隐马尔可夫模型识别方面起主导作用,而日本则在大词汇表连续语音神经网络识别、模拟人工智能进行语音后处理方面处于主导地位。
我国在七十年代末就开始了语音技术的研究,但在很长一段时间内,都处于缓慢发展的阶段。直到八十年代后期,国内许多单位纷纷投入到这项研究工作中去,其中有中科院声学所,自动化所,清华大学,四川大学和西北工业大学等科研机构和高等院校,大多数研究者致力于语音识别的基础理论研究工作、模型及算法的研究和改进。但由于起步晚、基础薄弱,计算机水平不发达,导致在整个八十年代,我国在语音识别研究方面并没有形成自己的特色,更没有取得显著的成果和开发出大型性能优良的实验系统。
但进入九十年代后,我国语音识别研究的步伐就逐渐紧追国际先进水平了,在“八五”、“九五”国家科技攻关计划、国家自然科学基金、国家863计划的支持下,我国在中文语音技术的基础研究方面也取得了一系列成果。
在语音合成技术方面,中国科大讯飞公司已具有国际上最领先的核心技术;中科院声学所也在长期积累的基础上,研究开发出颇具特色的产品:在语音识别技术方面,中科院自动化所具有相当的技术优势:社科院语言所在汉语言学及实验语言科学方面同样具有深厚的积累。但是,这些成果并没有得到很好的应用,没有转化成产业;相反,中文语音技术在技术、人才、市场等方面正面临着来自国际竞争环境中越来越严峻的挑战和压力。
语音识别系统的结构
主要包括语音信号的采样和预处理部分、特征参数提取部分、语音识别核心部分以及语音识别后处理部分,图中给出了语音识别系统的基本结构。

语音识别的过程是一个模式识别匹配的过程。在这个过程中,首先要根据人的语音特点建立语音模型,对输入的语音信号进行分析,并抽取所需的特征,在此基础上建立语音识别所需的模式。而在识别过程中要根据语音识别的整体模型,将输入的语音信号的特征与已经存在的语音模式进行比较,根据一定的搜索和匹配策略,找出一系列最优的与输入的语音相匹配的模式。然后,根据此模式号的定义,通过查表就可以给出计算机的识别结果。
语音识别系统的分类
根据识别的对象不同,语音识别任务大体可分为三类,即孤立词识别(isolated word recognition),关键词识别(或称关键词检出,keyword spotting)和连续语音识别。
孤立词识别的任务是识别事先已知的孤立的词,如“开机”、“关机”等;连续语音识别的任务则是识别任意的连续语音,如一个句子或一段话;连续语音流中的关键词检测针对的是连续语音,但它并不识别全部文字,而只是检测已知的若干关键词在何处出现,如在一段话中检测“计算机”、“世界”这两个词。
根据针对的发音人,可以把语音识别技术分为特定人语音识别和非特定人语音识别,前者只能识别一个或几个人的语音,而后者则可以被任何人使用。显然,非特定人语音识别系统更符合实际需要,但它要比针对特定人的识别困难得多。
另外,根据语音设备和通道,可以分为桌面(PC)语音识别、电话语音识别和嵌入式设备(手机、PDA等)语音识别。不同的采集通道会使人的发音的声学特性发生变形,因此需要构造各自的识别系统。
语音识别技术类型
目前具有代表性的语音识别技术主要有动态时间规整技术(DTW)、隐马尔可夫模型(HMM)、矢量量化(VQ)、人工神经网络(ANN)、支持向量机(SVM)等技术方法。
动态时间规整算法(DynamicTime Warping,DTW)
是在非特定人语音识别中一种简单有效的方法,该算法基于动态规划的思想,解决了发音长短不一的模板匹配问题,是语音识别技术中出现较早、较常用的一种算法。在应用DTW算法进行语音识别时,就是将已经预处理和分帧过的语音测试信号和参考语音模板进行比较以获取他们之间的相似度,按照某种距离测度得出两模板间的相似程度并选择最佳路径。
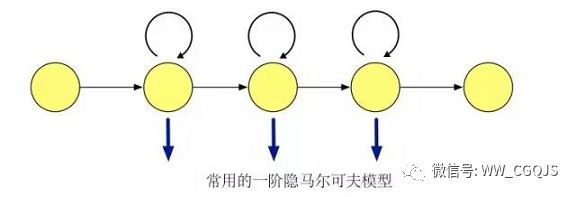
隐马尔可夫模型(HMM)
是语音信号处理中的一种统计模型,是由Markov链演变来的,所以它是基于参数模型的统计识别方法。由于其模式库是通过反复训练形成的与训练输出信号吻合概率最大的最佳模型参数而不是预先储存好的模式样本,且其识别过程中运用待识别语音序列与HMM参数之间的似然概率达到最大值所对应的最佳状态序列作为识别输出,因此是较理想的语音识别模型。
矢量量化(VectorQuantization)
是一种重要的信号压缩方法。与HMM相比,矢量量化主要适用于小词汇量、孤立词的语音识别中。其过程是将若干个语音信号波形或特征参数的标量数据组成一个矢量在多维空间进行整体量化。把矢量空间分成若干个小区域,每个小区域寻找一个代表矢量,量化时落入小区域的矢量就用这个代表矢量代替。矢量量化器的设计就是从大量信号样本中训练出好的码书,从实际效果出发寻找到好的失真测度定义公式,设计出最佳的矢量量化系统,用最少的搜索和计算失真的运算量实现最大可能的平均信噪比。
在实际的应用过程中,人们还研究了多种降低复杂度的方法,包括无记忆的矢量量化、有记忆的矢量量化和模糊矢量量化方法。
人工神经网络(ANN)
是20世纪80年代末期提出的一种新的语音识别方法。其本质上是一个自适应非线性动力学系统,模拟了人类神经活动的原理,具有自适应性、并行性、鲁棒性、容错性和学习特性,其强大的分类能力和输入—输出映射能力在语音识别中都很有吸引力。其方法是模拟人脑思维机制的工程模型,它与HMM正好相反,其分类决策能力和对不确定信息的描述能力得到举世公认,但它对动态时间信号的描述能力尚不尽如人意,通常MLP分类器只能解决静态模式分类问题,并不涉及时间序列的处理。尽管学者们提出了许多含反馈的结构,但它们仍不足以刻画诸如语音信号这种时间序列的动态特性。由于ANN不能很好地描述语音信号的时间动态特性,所以常把ANN与传统识别方法结合,分别利用各自优点来进行语音识别而克服HMM和ANN各自的缺点。
近年来结合神经网络和隐含马尔可夫模型的识别算法研究取得了显著进展,其识别率已经接近隐含马尔可夫模型的识别系统,进一步提高了语音识别的鲁棒性和准确率。
支持向量机(Supportvector machine)
是应用统计学理论的一种新的学习机模型,采用结构风险最小化原理(Structural Risk Minimization,SRM),有效克服了传统经验风险最小化方法的缺点。兼顾训练误差和泛化能力,在解决小样本、非线性及高维模式识别方面有许多优越的性能,已经被广泛地应用到模式识别领域。
语音识别技术的难点及对策
语音识别技术的发展,达不到实用要求的,主要表现在以下方面 :
(1) 自适应问题 。
语音识别系统的自适应性差体现在对环境条件的依赖性强。 现有倒谱归一化技术、相对谱(RASTA)技术、LINLOG RASTA 技术等自适应训练方法。
(2)噪声问题。
语音识别系统在噪声环境下使用,讲话人产生情绪或心里上的变化 ,导致发音失真、发音速度和音调改变 ,产生Lombard/Loud 效应。 常用的抑制噪声的方法有谱减法、环境规正技术、不修正语音信号而是修正识别器模型使之适合噪声、建立噪声模型。
(3)语音识别基元的选取问题 。
一般地,欲识别的词汇量越多,所用基元应越小越好。
(4 )端点检测。
语音信号的端点检测是语音识别的关键第一步。研究表明,即使在安静的环境下,语音识别系统一半以上的识别错误来自端点检测器。提高端点检测技术的关键在于寻找稳定的语音参数 。
(5 )其它如识别速度问题 、拒识问题以及关键词检测技术(即从连续语音中去除 “啊”、“唉”的语气助词,获得真正待识别的语音部分 )、对用户的错误输入不能正确响应等问题 。
语音识别的应用
语音识别可以应用的领域大致分为大五类:
办公室或商务系统。典型的应用包括:填写数据表格、数据库管理和控制、键盘功能增强等等。
制造业。
在质量控制中,语音识别系统可以为制造过程提供一种“不用手”、“不用眼”的检控(部件检查)。
电信。
相当广泛的一类应用在拨号电话系统上都是可行的,包括话务员协助服务的自动化、国际国内远程电子商务、语音呼叫分配、语音拨号、分类订货。
医疗。
这方面的主要应用是由声音来生成和编辑专业的医疗报告。
其他。
包括由语音控制和操作的游戏和玩具、帮助残疾人的语音识别系统、车辆行驶中一些非关键功能的语音控制,如车载交通路况控制系统、音响系统。
随着移动互联网技术的不断发展,尤其是移动终端的小型化、多样化变化趋势,语音识别成为区别于键盘、触屏的人机交互手段之一。随着语音识别算法模型、自适应性的加强,相信在未来很长一段时间内,语音识别系统的应用将更加广泛与深入,更多丰富的移动终端语音识别产品将步入人们的日常生活。

