

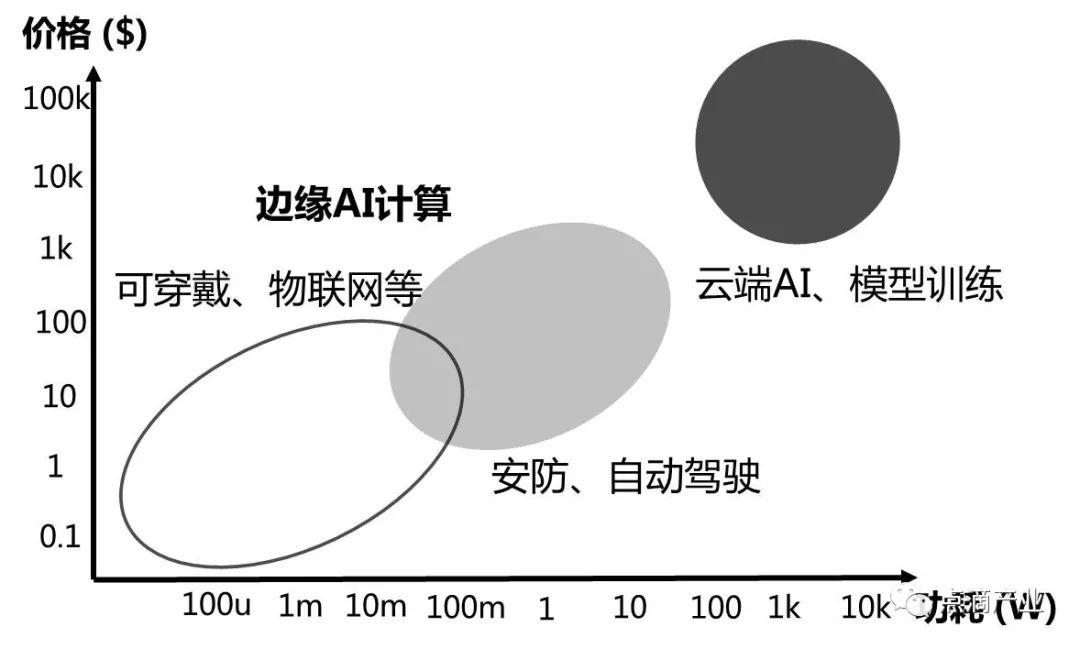
一、计算架构和存储的瓶颈
随着人工智能计算的需求剧增,现有计算架构遭遇功耗墙、性能墙、内存墙、摩尔定律趋缓等挑战迫切需要计算架构的创新,解决路径主要体现在两点:突破计算架构和打破存储墙。
计算架构的创新一直是争论的焦点,在应用上涌现的GPU、FPGA、ASIC、类脑甚至于3DSoC等,都是想打破适应性、性能、功效、可编程性和可扩展性等5个硬件特性的瓶颈,任何一个架构都不会在5个特性都达到最优。杜克大学陈怡然教授在2018人工智能计算大会上的观点我比较认同,抛开哪个架构最优,适合你的业务场景、数据类型、支出成本的架构,能让你的企业跑起来赚到钱的就是好的架构。
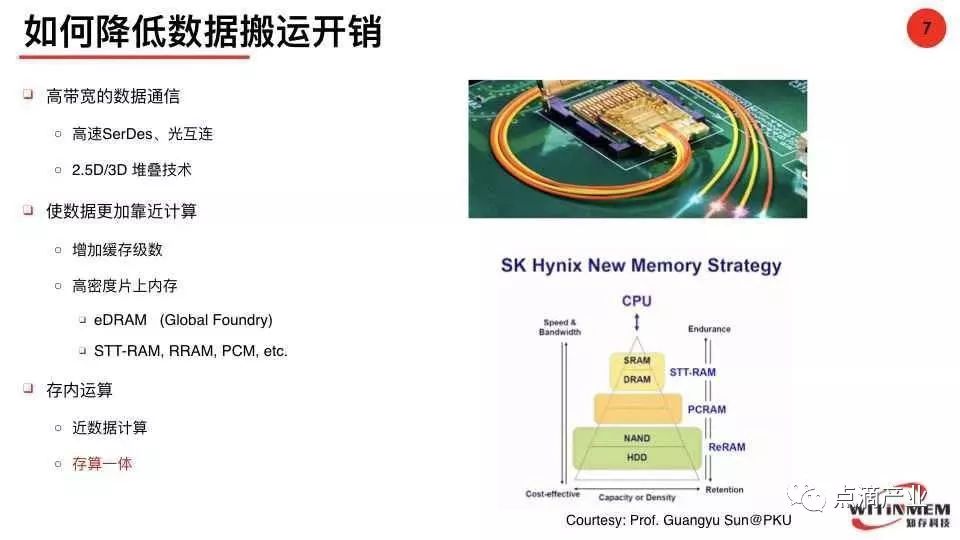
计算架构更新资金成本的提高、时间成本的延长和复杂度的提升,促使学术界和产业界转向研究“如何打破存储墙”,解决路径好多种,包括:
1. 高带宽的数据通信
高速SerDes:点对点的串行通信提升传输速度
光互连:信号间无感应、无干扰、速率高、密度大替代电互联
2.5D/3D堆叠技术:搭积木,不改变现有产品制程的基础上提高单位芯片面积内的晶体管数量,处理器周围堆叠更多的存储器件
2. 数据靠近计算
增加缓存级数:处理器和主存插入高速缓存,相对来说缓存越大速度越快,但成本高。
高密度片上内存:EDRAM动态随机存取内存、PCM相变存储的静态和非晶体转换
3. 存内运算
近数据计算:离数据更近的边缘侧进行计算处理。
存算一体:片外高带宽内存HBM、高带宽存储(3D-Xtacking,存储单元和外围电路在不同晶园独立加工)和片内(在存储器颗粒本身的算法嵌入)。
二、存算一体的原理、优劣势和应用
1.原理
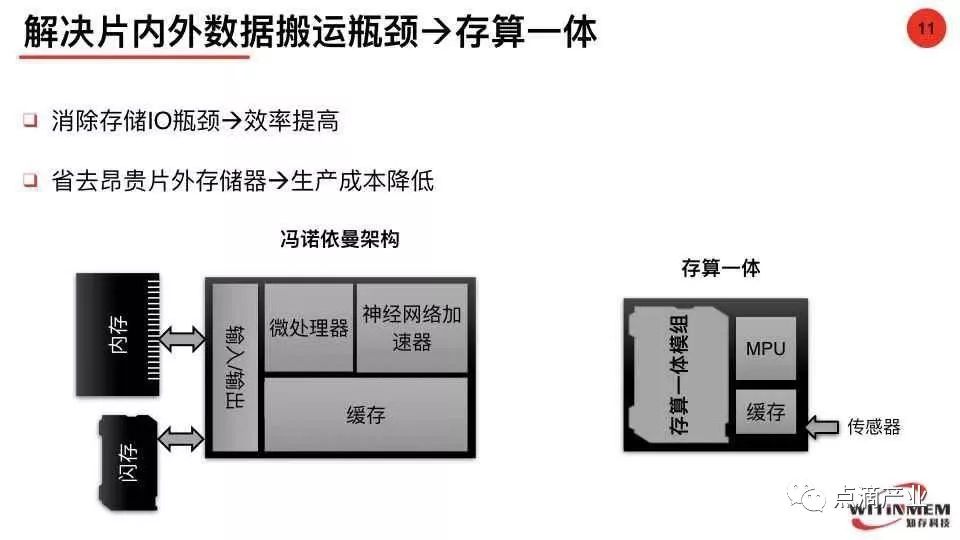
冯诺伊曼架构是计算机的经典架构,同时也是目前计算机以及处理器芯片的主流架构。在冯诺伊曼架构中,计算/处理单元与内存是两个完全分离的单元:计算/处理单元根据指令从内存中读取数据,在计算/处理单元中完成计算/处理,并存回内存。
存内运算的主要改进就是把计算嵌入到内存里面去,内存变成存储+计算的利器,在存储/读取数据的同时完成运算,减少了计算过程中的数据存取的耗费。把计算都转化为带权重加和计算,把权重存在内存单元中,让内存单元具备计算能力。陈怡然教授指出存内计算主要针对的是两个运算输入其中一个保持不变的场景,不是两个都随时在变的一般计算场景。在架构设计中重点在如何调节输入数据次序以适应不同的计算结构。
内存内计算对于人工智能芯片带来什么影响?首先,存内计算本质上会使用模拟计算,计算精度会受到模拟计算低信噪比的影响,通常精度上限在8bit左右,而且只能做定点数计算(精确到整数),难以做浮点数(精确到小数点)计算。所以,需要高计算精度的人工智能训练市场并不适合内存内计算,换句话说内存内计算的主战场是在人工智能推理市场。即使在人工智能推理市场,由于精度的限制,内存内计算对于精度要求较高的边缘服务器计算等市场也并不适合,而更适合嵌入式人工智能等对于能效比有高要求而对于精确度有一定容忍的市场。
第二,存内计算其实最适合本来就需要大存储器的场合。举例来说,Flash在IoT等场景中本来就一定需要,那么如果能让这块Flash加上内存内计算的特性就相当合适,而在那些本来存储器并不是非常重要的场合,为了引入内存内计算而加上一块大内存就未必合适,因此,存内计算有望成为未来嵌入式人工智能(如智能IoT)的重要组成部分。
第三,存算一体芯片解决计算瓶颈问题,本质是乘积累加运算(Multiply Accumulate, MAC)操作加快的体现。乘积累加运算是在数字信号处理器或一些微处理器中的特殊运算,现在是在存储器实现此运算操作的硬件电路单元,被称为“乘数累加器”。这种运算的操作,是将乘法的乘积结果和累加器A的值相加,再存入累加器,以节省整个乘加操作的执行延迟。
2.驱动力
存算一体的商业驱动力,换句话说为什么火了,主要是源于深度学习对存储器的需求、深度学习易于并行计算、深度学习市场潜力推动人工智能发展、摩尔定律的成本越来越高。
杜克大学陈怡然教授指出存内计算为什么火了:是因为出现了以深度学习为代表的应用。一个典型运算包括两个运算输入和一个运算操作。之前的很多科学计算应用两输入都是实时产生的,存内计算意义不大。神经网络的权重是固定的,只有输入是实时产生的,才产生了将权重存在内存,等外部输入进入后再计算的存内计算的需求。
3.类型及优劣势
(1)片外存储(基于数字芯片和存储器配合的存算一体)
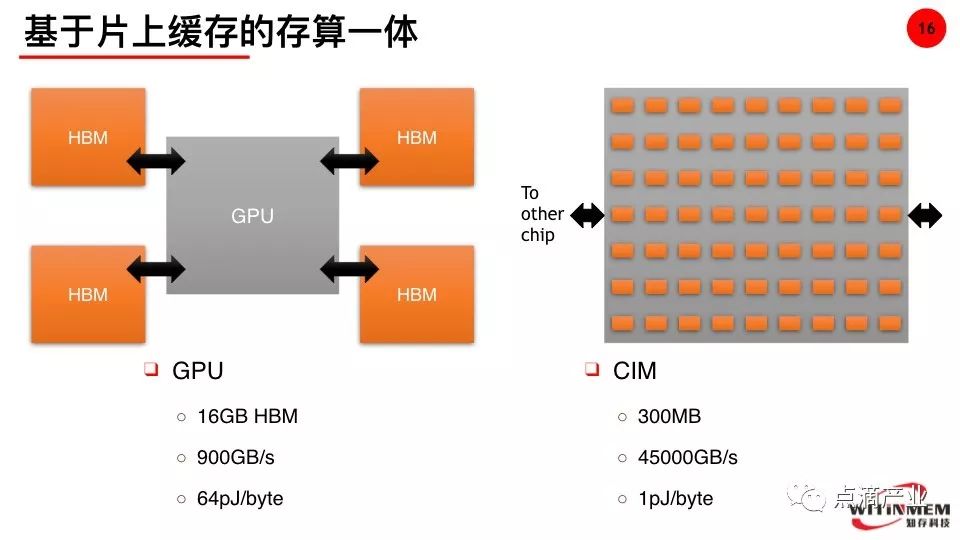
①高带宽内存HBM:
对于GPU来讲,采用3D的DRAM和GPU金属线连接,提高通信速度(900GB/S),但功耗高、成本高。
对于其他芯片来说,用SRAM替代HBM(3D DRAM)降低能耗和提升读写速度,成本高。这种情况用大量的SRAM可以匹配大量的MPU和CPU等处理器,提升运行的效率。陈怡然教授指出SRAM为基础的存内计算很可能仅具有演示意义,原因是SRAM单元本身的scalability和可靠性。
②新型存储拓宽内存:
使用新型存储器布局在处理器周围拓展内存,比如磁存储(MRAM)降低成本、提升存储密度,断电数据不丢失,工艺仅多提高3-4层MASK,性能有效提升,达到约10Tops/W(每瓦特10万亿次运算)。
(2)片内存储(数模混合的存算一体化)
片内存储就是在存储器颗粒嵌入算法权重MAC,将存储单元具备计算功能,并行计算能力强,加上神经网络的对于计算精度的误差容忍度较高(存储位数可根据应用调整),因此存内计算数字和模拟混合即使带来误差对于符合的应用性能和能效比合适,带来存内计算和人工智能尤其深度学习的广泛结合。
①相变存储PCM
相变存储器通常是改变加热时间促进硫族化合物在晶态和非晶态巨大的导电性差异来存储数据,相变时间100-1000ns,可擦写次数达到108,现在新型材料涌现的越来越多。
②阻变存储器/忆阻器 RRAM/Memristor
忆阻器,是一种有记忆功能的非线性电阻,它的电阻会随着流过的电流而改变。在断电之后,即使电流停止了,电阻值仍然会保持下去,直到反向电流通过,它才会返回原状。所以,通过控制电流变化可以改变它的阻值,然后例如将高阻值定义为“1”,低阻值定义为“0”,就可以实现数据存储功能。人们通常将它用于构建高密度非易失性的阻变存储器(RRAM)。
忆阻器网络,与生物大脑的神经网络相似,可以同时处理许多任务。最重要的是,它无需反复移动数据。它可以并行地处理大量信号,特别适合于机器学习系统。编程时间大概10-1000ns,可编程次数106-1012次。
③浮栅器件
浮栅器件工艺成熟,编程时间10-1000ns,可编程次数105次,存储阵列大,实现量产运算精度高、密度大、效率高、成本低,适宜深度学习和人工智能使用。
结论:存内计算的优势最大优势是消除了从旁边的存储器把数据load到计算单元的过程。基于新型存储器的存内计算最大的优势有三个:1)存储单元小得多(SRAM要6-10个晶体管,还不算存内计算需要额外加上的计算单元);2)存储单元就是计算单元,等于消灭了计算单元和它带来的开销;3)最重要的是非易失性。SRAM电源一关马上数据就消失,而新型存储器里的数据会一直保持,比每次开启都要从Flash里面读取数据快多了,让存内计算有无限的应用想象空间。
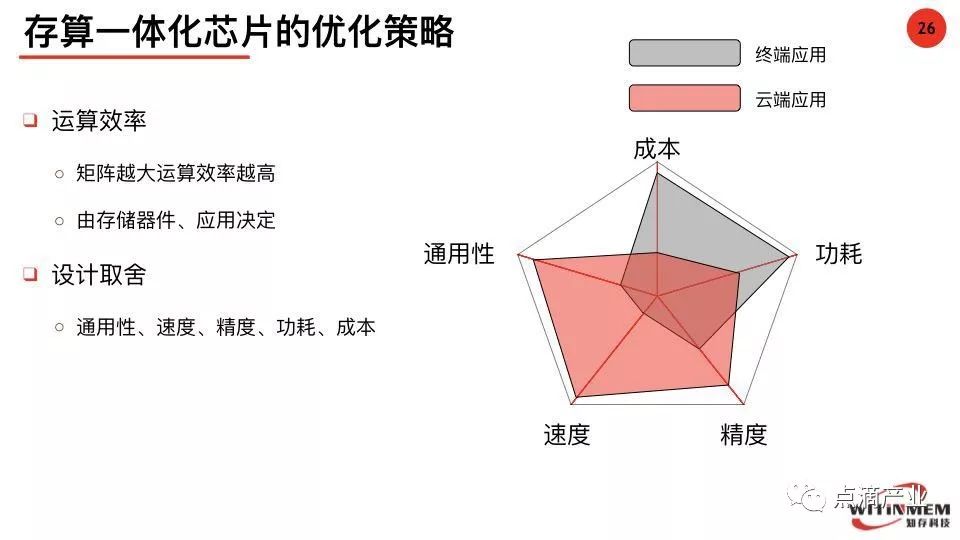
3.芯片优化策略
终端存算一体芯片推理应用需要更低的成本、更低的功耗,对于精度、通用性要求不高。
云端存算一体芯片训练应用需要通用性、速度和精度要求,因此目前存算一体芯片精度不高情况下适宜前端的嵌入式应用。
4.存算一体芯片挑战
(1)现有浮栅器件存储不适合计算,需要优化和改进。
(2)新型存储器的进展挑战浮栅器件,会有更适合存算一体的可能。
(3)存算一体目前在8bit运算精度,在适宜的条件下需提升运算精度,比如Nor Flash做到10bit。(陈怡然教授提出“为什么CMOS能高精度而新型存储器不能,SRAM和DRAM都不能提高精度!只有Flash可以!但Flash有编程复杂度、功耗、稳定性和寿命的问题。ReRAM和PCM是真的多比特编程,现在基本可以实现2比特存储。好多VC问我新型存储器啥时候能提高到8比特。我想说Flash大规模商用从单比特到三比特用了超过十五年,微电子与互联网还不太相同,需要时间成本和耐心。)
(4)存算一体芯片与开发环境、架构和现有工艺的兼容需要市场和时间。
(5)性能与场景结合需要落地。
5.存算一体的未来
(1)低精度但准确的乘法和累加运算带来端的效率提升,芯片成本降低,目前Nor Flash在40nm/55nm工艺下即可,但Nor 会一定程度限定应用,不过未来开发更优化器件和工艺就可突破。
(2)存算一体芯片的投资机构包括软银、英特尔、微软、博世、亚马逊甚至美国政府,中国存算一体的知存科技将获得下一轮的投资,同时还有清华忆阻器的新忆科技。
(3)存算一体芯片第一代产品都瞄准语音,未来都将切入安防和细分市场,但。
(4)存算一体企业模式应分为两种模式:一是销售IP,二是做AI存算一体芯片,前者单纯IP日子将非常难过。未来还是做芯片吧!不过各类竞争也不小。
(5)目前存算一体的极限效率为>300Tops/W(8bit),现在工业界差距较大5-50Tops/W,进步空间大。
(6)浮栅器件在摩尔定律带动下朝着更高工艺发展,比如从40-14nm过渡,性能将大幅提升。新型存储器将从28-5nm工艺过渡,提升工艺性能。
(7)存储器工艺将朝着2X甚至10X及结构优化提升存算一体性能。
(8)精度的提升如何实现转陈怡然教授:真想实现高精度短期靠多堆几个单元上去就好了,只是功耗会大点,只是推理其实现在的精度足够了。
(9)几乎所有的大半导体公司和foundry都在做相关研究,不少foundry也已经开始支持新型存储器制造技术,和CMOS全兼容。做基于新型存储器的存内计算的商业化正在风口。
6.存算一体的应用
低功耗持续运行的物联网设备,比如智能家居、可穿戴设备、移动终端及感知计算、智慧城市需要的低功耗边缘计算设备。
三、存算一体的重要玩家
1.IBM
IBM在相变存储(PCRAM)里实现神经网络计算的功能,利用新型存储器件的模拟计算功能来实现神经网络的计算。
2.加州大学圣芭芭拉分校谢源教授
谢源教授的研究团队在新型存储器件ReRAM(阻变存储)里面做计算的功能,让存储器件做神经网络的计算,称之为PRIME架构。2018年谢源团队和新竹清华大学张孟凡教授团队以及北京清华大学刘勇攀教授团队和汪玉教授团队合作,把PRIME的架构在150nm工艺下流片,在阻变存储阵列里实现了计算存储一体化的神经网络,功耗降低20倍,速度提高50倍。
谢源教授和三星存储研究部门推出DRISA架构就是在DRAM的工艺上,实现了卷积神经网络的计算功能。
3.加利福尼亚州欧文市的Syntiant
位于美国加利福尼亚州的AI芯片初创企业Syntiant打造一类全新的超低功耗、高性能深度神经网络处理器,Syntiant的神经决策处理器(Neural Decision Processor,NDP)没有传统处理器架构的限制,使用模拟神经网络,该网络可以通过极高的内存效率实现极低的功耗,并且具有大规模并行乘法累加计算的能力。Syntiant声称与传统的数字存储架构相比,使用整个网络的模拟电路,希望达到20TOPS/W,Nvidia Volta V100 GPU可以达到0.4TOPS/W,NPD的效率提高提高了约50倍。Syntiant的第一批产品已经成功流片,该公司在2018年早些时候演示了一个原型NDP,它可以同时支持数十种应用程序定义的音频和关键字分类,使开发人员能够创建定制的始终在线的语音用户界面。同时,该处理器针对音频数据速率进行了优化,能够进行扬声器识别,音频事件检测、环境分类、传感器分析,并开始研发其第二代芯片,将扩大Syntiant技术在视频方面的应用,该芯片是20 tera-operations/watt 的NPD,计划于2019上半年开始提供样品。2018年10月Syntiant获得由M12(前身为微软风险投资公司)领投的2500万美元B轮融资,其它战略投资者包括亚马逊Alexa基金、应用创投(Applied Ventures)、英特尔资本、摩托罗拉解决方案风险投资、博世风投。
4.德克萨斯州奥斯汀的Mythic
Mythic环绕着带有可编程数字电路的模拟闪存阵列,目标是每次乘法和累加运算仅消耗0.5焦耳,每瓦特可支持约4万亿次操作(TOPS/W)。2018年3月,Mythic宣布完成了由SoftBank Ventures领导的4000万美元的投资,以帮助将高速,低功耗AI芯片推向市场。Lockheed Martin Ventures对Mythic进行了战略投资。此轮融资包括来自Mythic现有投资者Draper Fisher Jurvetson,Lux Capital,Data Collective和AME Cloud Ventures。Sun Microsystems联合创始人Andy Bechtolsheim(曾是谷歌的早期投资人)也有所参与。Mythic计划在今年年底之前出厂第一批硅片样品,并于2019年全面投产。
5.知存科技
知存科技成立于2017年10月的知存科技,成为国内存算一体的标志企业,获得兆易创新、启迪方信、科大讯飞等投资,第一款芯片预计2019年量产,面向超低功耗语音识别,将达到三十倍功耗降低,三倍生产成本降低,未来将开发视频和图像AI芯片和加速卡、人机交互物联网芯片。
6.新忆科技
新忆科技成立于2018年,清华大学背景,致力于忆阻器的研发和产业化,清华华控投资。
参考文献:
1.《内存内计算,下一代计算的新范式?》 来源:半导体行业观察。作者:李飞
2.《存算一体AI芯片的架构创新与技术挑战》 来源:知存科技公开课。作者:知存科技CEO 王绍迪

