



报名提醒


8月8日,NVIDIA创始人黄仁勋在SIGGRAPH现场发表NVIDIA主题演讲中谈到,通用计算将要让位给加速计算和AI计算。未来,大语言模型将几乎被应用于所有前端,几乎所有应用程序、数据库,而当人与计算机交互时都要先通过大模型。
黄仁勋宣布推出下一代版本的GH200 Grace Hopper超级芯片,该芯片将成为世界上第一个配备HBM3e(High Bandwidth Memory 3e)内存的GPU芯片。
最新版本的GH200超级芯片内存容量增加了3.5倍,带宽增加了3倍;相比最热门的H100芯片,其内存增加1.7倍,传输频宽增加1.5倍。

下一代版本的GH200 Grace Hopper超级芯片将成为世界上第一个配备HBM3e内存的GPU芯片。
围绕生成式AI,NVIDIA的软件部署
关于工作整合便捷高效方面,SIGGRAPH现场黄仁勋发布了一个全新的工作空间NVIDIA Workbench,该平台可以简化选择基础模型,构建项目环境,使用户能够在个人电脑或工作站上快速创建测试和微调生成式AI模型,然后将这些模型扩展到几乎所有数据中心或云中,帮助使用者构建大型语言模型。
关于为每个人提供生成式AI方面。英伟达将与初创企业Hugging Face合作,帮助使用者构建大型语言模型等高级AI应用,意味着使用者将可以免费使用GPT340个参数的微调和推理,生成自己的大语言模型,或将其用于生成和合成图像等其他用途。
关于AI在虚拟世界中的应用。黄仁勋宣布,NVIDIA Omniverse的重量更新,为开发者、企业和行业带来新的基础应用和服务,使他们能够使用openu SD框架和生成式AI,优化改进3D流程。
关于世界产业的可视化。黄仁勋发布包括RunUSD、ChatUSD、DeepSearch和USB-GDN Publisher在内的四款全新Omniverse Cloud API,使开发者能够更加流畅,实施和部署open USD流程和应用,这意味着重工业的整个生产流程,可以实现可视化,减少能源损耗以及实际制造前的数字错误。
预炼大模型,先囤卡
在黄仁勋发表的最新演讲和发布的产品中,我们看到了英伟达在软件部署上的野心。事实上在AI领域,英伟达GPU早已成为核心基础设施,是各家企业大模型训练的必要硬件工具。
自ChatGPT火爆出圈以来,国内外科技巨头纷纷布局大模型。
根据《中国人工智能大模型地图研究报告》分析,中国自2020年进入大模型加速发展期,目前与美国保持同步增长态势,涌现了盘古、悟道、文心一言、通义千问、星火认知等一批具有行业影响力的预训练大模型。
对大模型来说,通常需要更多的计算资源进行训练和推理,才能提供更高的性能和更好的准确性。这就意味着,随着通用大模型的参数量和计算复杂度不断增加,数亿甚至数十亿个参数的模型也变得更加常见。目前,中国10亿参数规模以上的大模型已发布79个。
每一个大模型正常运转的背后,都需要算力加持,算力需求的暴涨让跟算力“划等号”的高端GPU一芯难求,“算力”军备竞赛正在全球范围内上演。
目前,高端GPU价格仍在上涨,在eBay网站上英伟达H100售价高达4.5万美元,约合32万人民币,较官网售价涨幅23%(3.65万美元,约合26万人民币),较4月4万美元的价格涨幅超过10%。
H100是英伟达2022年推出的加速卡,比上一代的A100性能高了4.5倍,考虑到训练和推理性能,是当前最受欢迎的显卡。
H100,有钱也不一定买得到
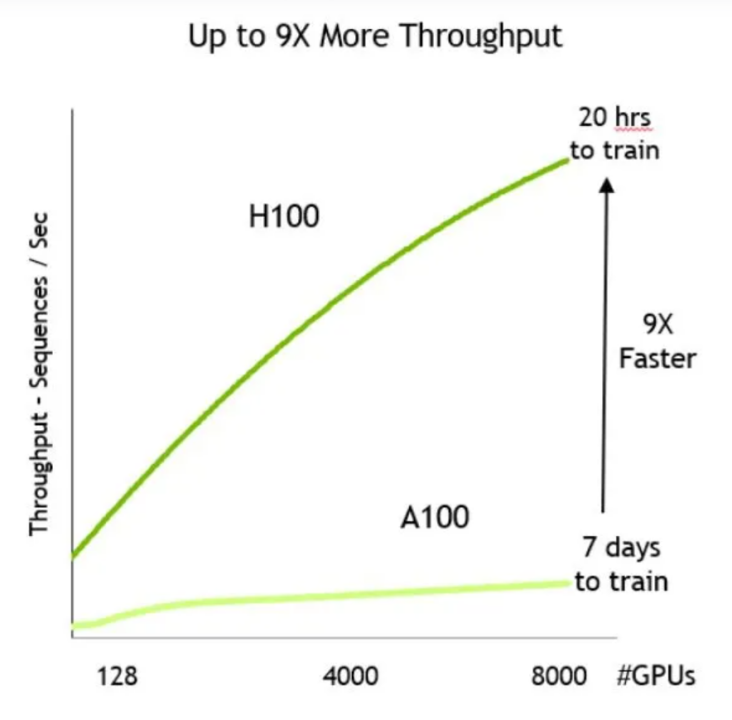
图:A100 vs H100 训练速度
国内方面,受芯片出口管制影响,英伟达A100及H100两款型号国内不能买到。所以NVIDIA推出了专供中国的A800和H800,实际性能只有前者的7成左右,在符合限售禁令的同时亦满足中国市场GPU需求。
国外方面,主要是需求旺盛叠加产能不足,导致GPU短缺。根据GPU Utils关于英伟达H100显卡供需现状文章,分析认为全球市场对H100芯片的需求量达到43.2万张,以每块3.5万美元计算,GPU的价值约为150亿美元,这还未考虑国内H800的需求。
目前,H100由台积电独家代工生产,英伟达黄仁勋在今年6月台北电脑展上表示,不会考虑新增第二家晶圆代工,因此英伟达 A100 / A800 及 H100皆下单台积电。虽然英伟达后又追加订单,但由于从晶圆加工到封装测试至少需要4个月的时间,产能短期仍无法满足暴涨的需求。
8月2日,OpenAI已经正式为“GPT-5”提交了商标申请,此举可能预示着OpenAI计划推出新的大型语言模型(LLM)“GPT-5”。马斯克估计训练GPT-5,可能需要3万至5万张H100显卡。
OpenAI首席执行官奥尔特曼(Sam Altman)近日公开表示:“我们的GPU非常短缺,使用ChatGPT的人越少越好,这样才能确保用户有足够的算力。”
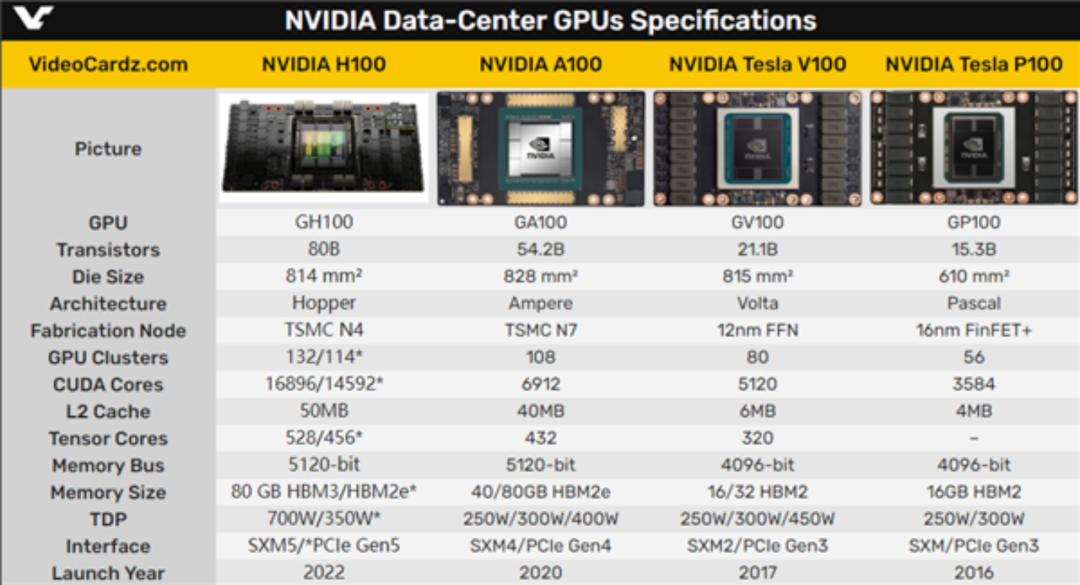
两条路径:GPU和GPGPU
一开始,GPU专注于图像渲染处理,由英伟达在1999年发布GeForce 256图形处理芯片时率先提出,当时GPU主要面向的是游戏和PC市场。
由于GPU架构内主要为计算单元,适合处理高度线程化、相对简单的并行计算,在图像渲染等涉及大量重复运算的领域拥有更强运算能力。因此,英伟达在后期又进一步将计算机程序模拟为渲染过程,将GPU应用于通用并行计算,并于2007年推出了基于CUDA的GPGPU (通用GPU)beta版。
自此,GPU不再局限于图形处理的游戏和PC市场,并随着AI的兴起,GPGPU在AI领域大行其道。
目前,英伟达GPU在图形渲染领域与AMD并驾齐驱;但在通用GPU领域英伟达一骑绝尘,市场占有率超80%,几乎成为该领域无可替代的存在。
在高端 GPU 芯片进口受限的背景下,国内GPU厂商近些年奋力追赶,在图形渲染 GPU 和高性能计算GPGPU 领域上均推出了较为成熟的产品。
GPGPU方向的代表性厂商像海光、壁仞、沐曦、登临、天数智芯等,GPU渲染路线的代表性厂商像景嘉微、摩尔线程、芯动科技等。
国内GPU厂商中壁仞、天数智芯、沐曦等均已推出采用7nm工艺的GPU,芯瞳半导体、芯动科技、摩尔线程等公司也相继推出GPU产品。原CPU厂商龙芯、海光等也在加注GPGPU,不过龙芯GPGPU主要是集成在自家SOC中,预计2024年龙芯将流片。
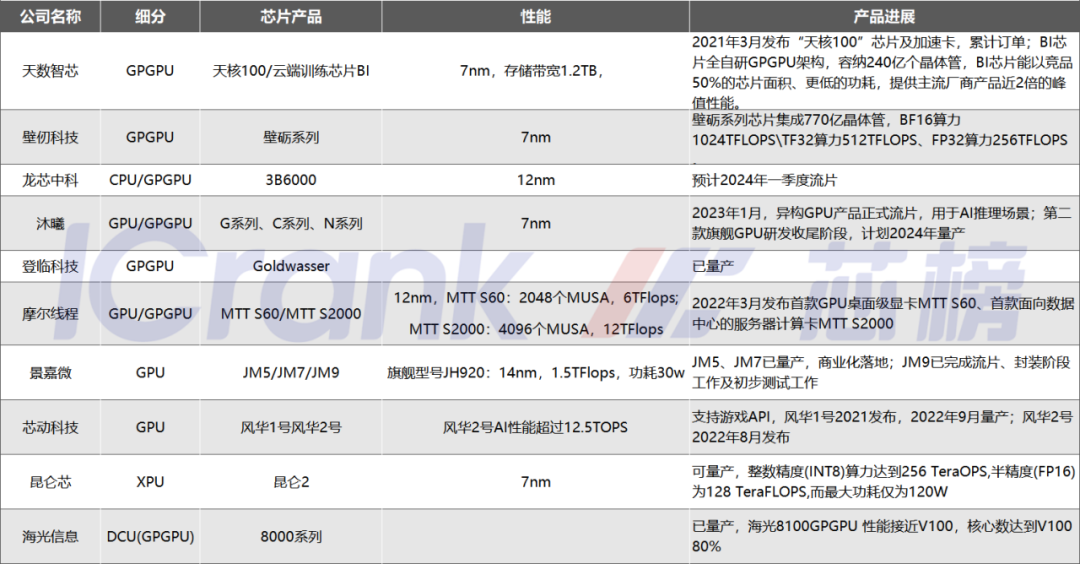
图:国产GPU厂商产品进展;来源:根据公开资料整理,芯榜制图
这当中大部分企业属于初创期,成立时间不足5年,在产品可用性及市场规模上都与国外大厂相差甚远。如果用一句话总结,国内GPU厂商当下处于“从0到1”的阶段,通过快速迭代,拉进与国外大厂的差距,以形成自身竞争力。
国产GPU在硬件性能上不断追赶行业主流产品,但若细化到产业中,仍有三大难题待解。
资金、产业链协同、软硬件生态的三大难题
先说资金,一级市场融资解决了一部分初创企业资金难问题。
IT桔子数据显示,2020-2022年是国产GPU投融资大年。国产GPU融资在2021年迎来峰值,总融资额突破120亿人民币,即便2022年融资总额较前一年缩减50%,但仍为近8年GPU行业融资金额第二的年份。
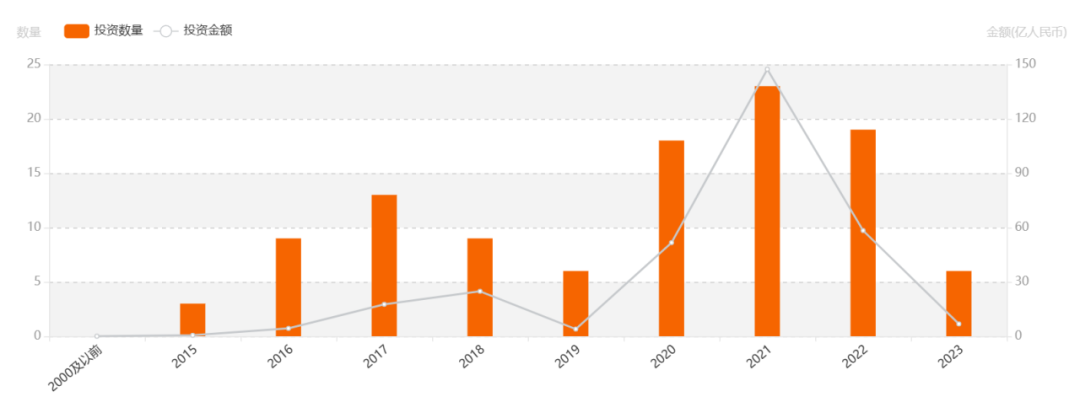 来源:IT桔子,GPU芯片融资
来源:IT桔子,GPU芯片融资
虽然,众多成立2-3年的初创公司获得多轮巨额融资,但相较GPU芯片研发烧钱程度来说,还是杯水车薪。业内人士向芯榜透露,一款GPU从设计到落地,整体花费大致需要20几亿人民币(包含人工)。
芯榜整理了近几年来GPU厂商融资情况,排名靠前的为摩尔线程、壁仞科技、沐曦、天数智芯。如果对照上文中“国产GPU厂商产品进展”,可以发现融资顺畅的GPU厂商,产品进展也相对较快。
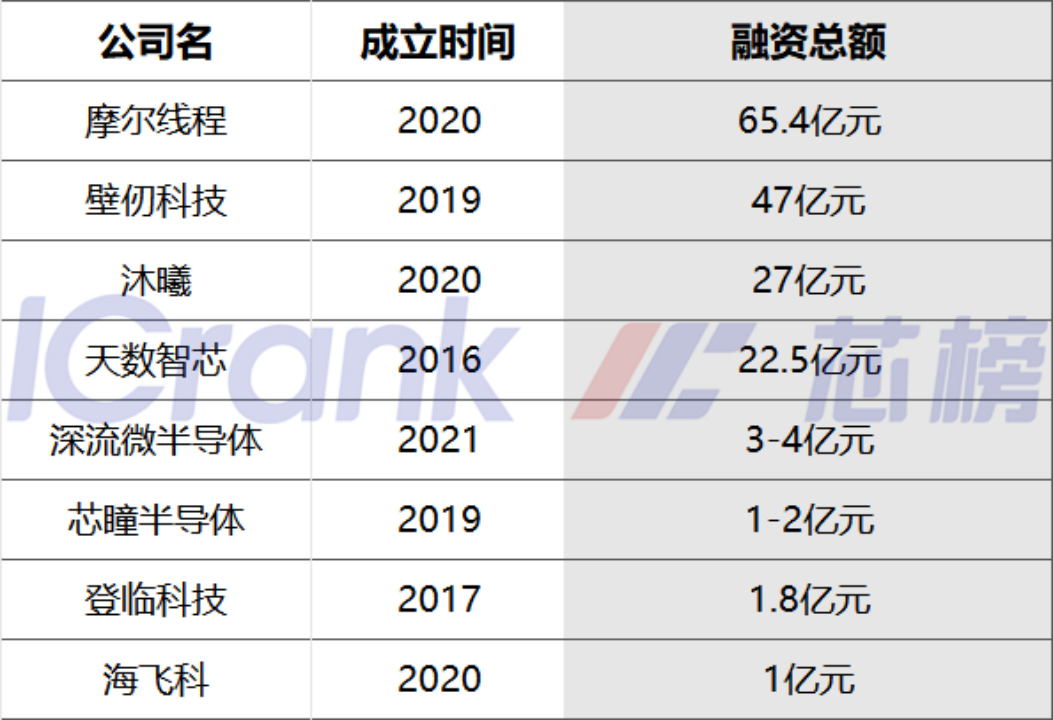 来源:公开资料整理,芯榜制图
来源:公开资料整理,芯榜制图
注意,这里未公开的融资金额未计入。例如,登临科技从2020年3月天使轮至今,已完成融资6轮,但由于融资金额“未公开”,因此未计数。上图中统计融资金额,若有遗漏,欢迎指正。
资金问题相对好解决,但并不是“烧钱”就有GPU可用。除了资金问题,国产GPU真正需要解决两大问题是产业链协同、软硬件生态。
GPU产品从开发设计到流片到反片调优,最后正式发布,经历这一完整周期,大概需要一年半或两年甚至更长的时间,中间涉及众多环节。
以流片为例,现阶段国产GPU厂商设计的7nm芯片,国内代工厂由于技术问题尚且无法提供流片服务,那么GPU厂商大概率还是选择先进工艺成熟的台积电流片。
据业内人士透露,初创企业找台积电流片,不仅要付2-3亿元高额代工费,流片需要的材料还需要自己找,然后带着材料去台积电流片。流片环节处于芯片设计和芯片量产的中间阶段,是芯片量产的必经之路,对GPU初创企业来说,即便请台积电流片的条件苛刻,但也无可奈何。
芯片流片前后过程至少持续三个月(包括光刻、掺杂、电镀、封装测试),一般要经过1000多道工艺。而若一次流片不成功,还需二次流片、三次流片……不仅烧钱,还耗费时间。
尤其是GPU作为一款数字芯片,遵循摩尔定律,约每隔18个月,机体电路上可容纳的晶体数目便会增加一倍,性能也将提升一倍。而在“自己卷自己”的“黄氏定律”推出后,基于GPU的一倍性能提升只需要1年的时间。
想想看,国产GPU公司团队可能刚组建完毕,产品demo还没做出来,国外头部GPU厂商产品已更新换代。所以,GPU作为一种跟时间赛跑、跟友商激烈竞争的产品,国产GPU企业在设计产品时,必须要具备一定的前瞻性,才有可能在市场中占据一席之地。不然耗时2年,消耗几十亿的产品可能即便顺利量产,最终或因性能落后无法被市场所接受。
英伟达H100采用4nm工艺,国内GPU最先进制程为7nm工艺,制程工艺的差距除了GPU设计企业需要努力外,国内供应链代工环节的技术差距或许短期内更难突破。半导体全产业协同作战,才有可能逐步缩短跟国外大厂的差距。
对于国产GPU公司,产品性能是一个门槛,另一个门槛是易用性,这就涉及到生态问题。英伟达经过20多年的发展,已经形成了强大的生态护城河CUDA。国内GPU厂商尚处于发展初期,急于攻克硬件,而忽视了软件问题。
事实上,一款GPU是否易用、好用,软件极为重要。好的软件能够驱动硬件能力,优化软件后,硬件得以跑出更好的性能和效率。目前国产GPU生态还属于新生状态,硬件和软件的相互迭代过程并不是一蹴而就,需要长时间的积累。国产GPU之路,注定是一场马拉松式的赛跑。短期2-3年或许能攒出一个硬件,但真要做到易用、好用,还要在生态、应用层面做大量的研发和优化。


报名提醒
