




当地时间周二(6月13日),超威半导体(AMD)如期举办了“AMD数据中心与人工智能技术首映会”,并在会上展示了其即将推出的AI处理器系列。
媒体分析称,AMD希望帮助数据中心处理更多的人工智能流量,挑战英伟达公司在这一新兴市场上的主导地位。首映会的重头戏自然是AMD推出的Instinct MI300系列。
公司CEO苏姿丰率先公布了MI300A,称这是全球首个为AI和HPC(高性能计算)打造的APU加速卡,拥有13个小芯片,总共包含1530亿个晶体管:24个Zen 4 CPU核心,1个CDNA 3图形引擎和128GB HBM3内存。

然后她还公布了对大语言模型进行了优化的版本——MI300X,内存达到了192GB,内存带宽为5.2TB/s,Infinity Fabric带宽为896GB/s,晶体管达到1530亿个。

苏姿丰表示,MI300X提供的HBM(高带宽内存)密度是英伟达H100的2.4倍,HBM带宽是竞品的1.6倍。

这意味着AMD可以运行比英伟达H100更大的模型,苏姿丰称,生成式AI模型可能不再需要数目那么庞大的GPU,可为用户节省成本。

另外,苏姿丰还发布了“AMD Instinct Platform”,集合了8个MI300X,可提供总计1.5TB的HBM3内存。为了对标英伟达的CUDA。

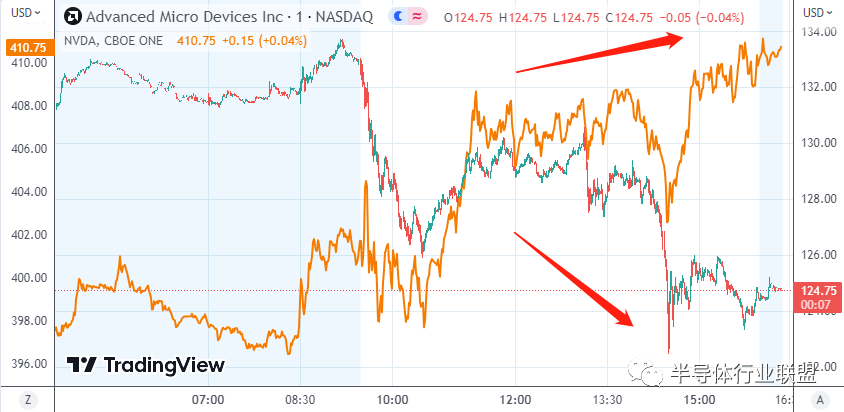
虽然苏姿丰很卖力地“推销”公司的新产品,但这似乎没有让金融市场满意。
AMD股价在活动过程中显著走低,收跌3.61%,而同行英伟达则收涨3.90%,市值首次收于1万亿关口上方。
AMD Instinct MI300加速处理器的参数其实早在2023年年初就被曝光。MI300是市场上首款“CPU+GPU+内存”的一体化产品,晶体管数量高达1460亿个,多于英伟达H100的800亿个,也是AMD目前生产的最大规模芯片。
据华泰证券测算,MI300的性能逼近英伟达的Grace Hopper芯片。虽然AMD暂时未公布MI300与Grace Hopper在算力上的对比,但相较上一代的MI250X,MI300在AI上的算力(TFLOPS)预计能提升8倍,能耗性能(TFLOPS/watt)将优化5倍。如果用这款处理器进行ChatGPT、DALL-E等超大型人工智能模型的训练,可以使训练时间从以往的几个月缩短至几周,从而节约数百万美元的电能。
苏姿丰在上个月的业绩电话会议上告诉投资者,MI300将在第四季度开始产生销售收入。
除此之外,AMD在发布会上表示,它也拥有自己的AI芯片软件(类似英伟达的CUDA),称为ROCm。AI开发人员历来更喜欢英伟达芯片的一个原因就在于CUDA,其大大降低了GPU的使用门槛,本来需要很专业的OpenGL的图形编程语言,有了CUDA以后,程序员常用的Java或者C++就可以调用GPU。由此,才有了GPU被用于深度学习。
“AI大神”吴恩达评价称,CUDA出现之前,全球能用GPU编程的可能不超过100人,有了CUDA之后使用GPU就变成了一件非常轻松的事情。
“虽然这是一个很长的过程,但在建立与开放模型、库、框架和工具生态系统的模型一起工作的强大软件堆栈方面,我们取得了非常大的进展。”AMD总裁彭明博(Victor Peng)表示。



