技术资源 Intel的四级缓存 VS AMD的3D缓存
Intel的四级缓存 VS AMD的3D缓存
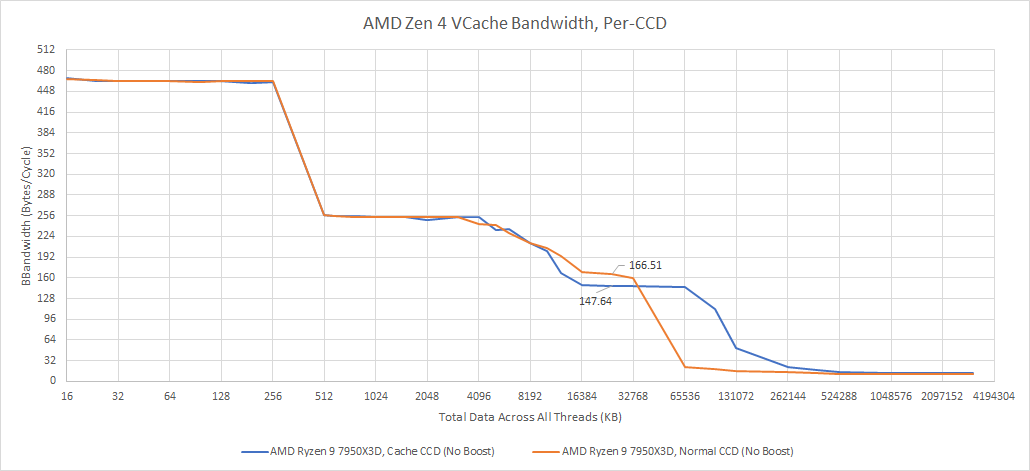
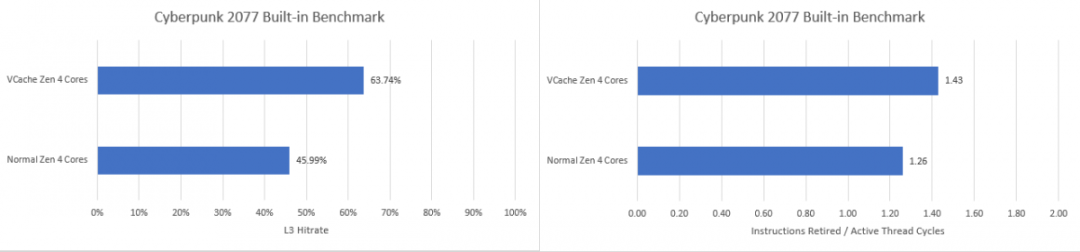
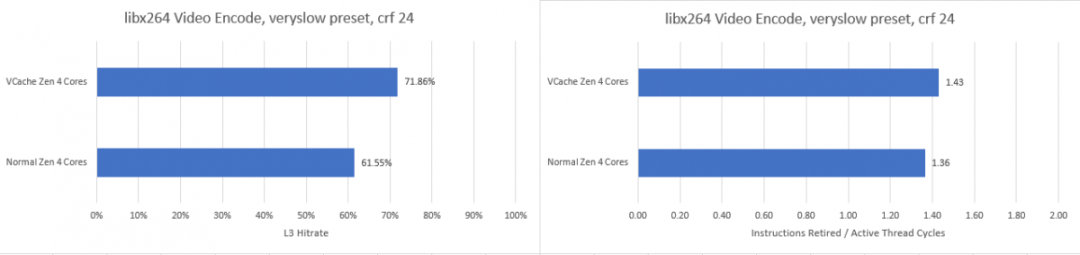
CPU在片内缓存——也就是cache方面下功夫,一直都是CPU微架构更新的老传统。这两年我们讨论最多的,莫过于AMD的3D V-Cache(以下简称V-Cache)——一种把L3 cache三级缓存垂直叠起来的方案,增大处理器的L3 cache容量。最近又有传言说,Intel接下来要发布的14代酷睿可能会采用L4 cache,也就是四级缓存。L4 cache虽说不能算是新东西,但在PC上仍然是稀罕玩意儿。有评论认为Intel给新一代酷睿增加L4 cache,是为了正面和V-Cache竞争。其实去年Chips and Cheese模拟过这种V-Cache可能带来的缓存访问延迟增加,及其在不同应用或负载中产生的负面影响。换句话说缓存堆料对某些类型的应用而言,反倒可能带来负加成。我们当时的观点是,AMD推出带V-Cache和不带V-Cache的不同处理器版本,对于用户而言,其本质更像是你更愿意为cache缓存容量买单,还是更愿意为core核心数买单,这两种倾向的应用场景是存在差异的。最近Chips and Cheese真正就这一代的AMD 7950X3D做了测试,得到了一个更有意思的结论。虽说这几天AMD Ryzen 7000系列似乎正深陷过载事件,不过我们还是期望借着Chips and Cheese的数据,以及14代酷睿L4 cache的传言,来谈谈“堆缓存”的价值,以及未来的PC客户端处理器缓存可能会变成什么样。大约半个月前,有个Linux补丁出现这样一段描述:这里的MTL就是指Meteor Lake,也就是14代酷睿;GT则应该是指Intel的核显GPU。后一个句子出现了L4 cache——只不过L4 cache前面的ADM暂不明是什么。前面一句话是说,在14代酷睿处理器上,核显不再能够获得LLC资源,仅有CPU可以。此处的LLC就是Last Level Cache,在一般的CPU上就是指L3 cache。有关这一点,我们此前撰文探讨过:14代酷睿处理器开始改用chiplet方案,其中核显(iGPU)所在的图形chiplet,和CPU所在的chiplet距离较远。以前Intel处理器的架构设计中,核显是挂在环形总线上的,所以核显也能和CPU共享LLC。而14代酷睿的chiplet式设计,就意味着核显无法再与CPU共享LLC——也就是L3 cache。这可能是14代酷睿打算开始用L4 cache的原因。而Linux补丁描述的后半句话出现的ADM/L4 cache实际上也是有迹可循的。国外媒体最近两天发现了Intel的一个新专利,其中提到代号为Adamantine的L4 cache用于某些CPU。这则专利提到,ADM cache不仅能够提升CPU和内存之间的通信性能,而且能提升CPU和安全控制器之间的通信。最终进行启动优化,甚至保持数据来减少加载时间。这则专利的示意图,出现了Gen 12.7、RWC(Redwood Cove)、CMT(Crestmont),这些基本透露了,这应该就是14代酷睿。从示意图来看,L4 cache可能位于base die。但不清楚这个四级缓存究竟会是多大容量的,也没有其他相关信息。对Intel处理器比较熟悉的同学应该知道,这并不是Intel首次在客户端CPU上给L3 cache之外新增一级中间存储介质。虽说目前我们对Meteor Lake之上的L4 cache具体情况尚不了解,但要说这是为了去和AMD的V-Cache竞争,恐怕也并不正确。V-Cache虽说也是L3 cache的扩充,但它仍然属于L3 cache——后文会给出Chips and Cheese测试的部分数据。它和L4 cache这种新增一级cache的做法可能还是有显著不同的。我们知道,多级cache设计方案在于越低层级的cache容量越大——其价值在于进一步提升cache命中率、隐藏处理器与内存交互的高延迟,但低层级的cache速度也会显著更慢。PC处理器没怎么大规模应用L4 cache的一大原因就在于它对系统性能的帮助可能十分有限。一般我们现在会提到的L4 cache,也已经是DRAM了,而不是SRAM。在PC上比较知名的L4 cache,应该出现在Intel Haswell微架构时代(2013年,第4代酷睿)。当时针对核显高配型号,Intel给这代处理器的封装内最多配了128MB的eDRAM(嵌入式DRAM),就可以看做是L4 cache。那为什么我们不说这是L3 cache的容量扩展呢?当年Intel处理器上的eDRAM作为一片单独的die(上图左边的die),从外部看都格外惹眼,这部分L4 cache是用于核显GPU和CPU做数据共享的,最初也作为L3 cache的victim cache。其实Intel的这种eDRAM设计是沿用到了Coffee Lake的(2017年,第8代酷睿)。只不过每一代架构应用此类方案的处理器型号也相当有限,所以知道L4 cache的人不多。Chips and Cheese这次也特别测试了Intel的这个eDRAM的几项重要数值,包括延迟和带宽。这两张图红线是AMD Ryzen 7950X3D的V-Cache,蓝线为Intel酷睿i7-5775C(Broadwell,第5代酷睿)的eDRAM。测试中,后者达到eDRAM访问深度的数据延迟超过了30ns,作为处理器侧的cache,属于相当高的延迟。而从带宽来看,eDRAM大约是50GB/s——这个量级也就是双通道DDR3内存的水平,也只有这颗处理器本身L3 cache大约1/4的带宽。当然这和架构设计还是有很大关系,涉及到eDRAM controller、OPIO传输等。这个结果并不让人意外,毕竟这两颗处理器存在着年代上的显著差异。这个对比应该是能够反映半导体技术的显著进步的,顺带也是看一看相隔大约10年,同样是CPU片上存储扩容方案,有着怎么样的变化。eDRAM相比于CPU其他层级的cache,属于很慢的一级cache。换句话说实际上,L3 cache还是作为隔离核心与eDRAM高延迟的存在。在Broadwell这代架构上,Intel为了更大程度消除eDRAM高延迟的影响,将L3 cache的一部分数据阵列用作L4的tag。如此一来L3控制器就能知道某个cache miss能否由eDRAM来解决。Skylake架构(2015年左右,第6代酷睿)上,eDRAM控制器放到了CPU的system agent之中,并有专门的tag。但Skylake时代的eDRAM比Broadwell还要糟,延迟更久、带宽则差不多。毕竟eDRAM说到底也还是个DRAM,需要刷新、跑起来也不快。这也决定了eDRAM就是个L4 cache,而不是L3 cache的扩容。14代酷睿要重新采用L4 cache,在设计上肯定和最初Haswell的eDRAM差别会很大;而且毕竟半导体技术经过了这么多年的进步,或许这次的L4 cache会带来惊喜。但既然叫做L4 cache,一般就意味着它比L3 cache更慢。不过说到底,eDRAM在PC处理器上的出现,更多也是为了强化核显性能所做的某种豪华存储配置。像游戏这类应用,存储介质的延迟要求天然地没有那么高,堆容量会显得更加有效。而且我们认为,Linux补丁也提到了核显与原本处理器的LLC脱钩了,这可能才是L4 cache在14代酷睿处理器上出现的主因。换句话说,未来基于chiplet的Intel处理器,可能会进一步强化核显GPU性能,L4 cache也是为其做准备的。另外L4 cache有较大概率和当年的eDRAM一样,是个可选项。所以Intel的L4 cache,与AMD的3D V-Cache并不具备多少可比性,两者的出发点就不同。但考虑到在PC平台上,这两位最终可能都是为游戏之类的图形应用所做的努力,总有那么点殊途同归的意思,即便达成的方式可能差别甚大。对V-Cache不了解的同学可以去看一看我们就V-Cache写过的好几篇文章,包括其3D封装的hybrid bonding混合键合方式。采用V-Cache的AMD处理器也可以说是台积电3D封装前沿技术的标杆了。简单来说,3D V-Cache是把更多的L3 cache,通过垂直堆叠的方式叠在了原本的CPU die上方。如此,处理器也就有了更大容量的L3 cache。在最初Chips and Cheese模拟大容量L3 cache会带来高延迟的负面影响时,我们对这种方案在PC平台上游戏之外的应用上也普遍不怎么看好。那会儿的AMD Ryzen 5800X3D还属于小试牛刀。今年Zen 4架构再用同类技术,似乎就显得相当驾轻就熟的,尤其过去存在的一些问题都被解决了。比如以前堆了V-Cache之后,CPU核心频率就没办法做得很高,也就很大程度影响到了对核心性能更敏感的应用。而这一代新产品(Ryzen 7000系列)极大程度受惠于5nm新工艺,各方面都得到了加强。就具体的产品来看,更高核心数的AMD处理器也能够堆V-Cache;更重要的是,核心频率不再像过去那么低。不过似乎是因为堆叠的V-Cache对于高压耐受力毕竟还是没那么高,所以我们看到AMD的客户端CPU产品,只有一部分核心上堆了V-Cache。比如说对于7950X3D这个型号,总共16个处理器核心——每8个核心作为一片die(CCD),这颗处理器也就有两片CCD。但实际上只有一片CCD(8个核心)上叠了V-Cache,另一片仍是普通的die。这种设计实际上造成了很有意思的一个事实:(1)16个核心中,其中有8个核心(假设为A组)有更大容量的cache;(2)但另外8个核心(假设为B组)的频率更高。虽然就核心架构角度来看,这16个核心是一样的;但因为存在cache容量与核心频率的差异,A、B两组核心看起来有了那么点异构的意思——虽然可能说异构是不合适的。像Intel那种一颗处理器有P-core、E-core两种不同架构的核心才能说是标准的异构核心CPU。但我们考虑这样一个事实:如果有一个应用,原本32MB L3就已经达到了较高的cache命中率,或者说其working set size非常大——大到即便堆了V-Cache,也并没有多少软用,则显然对这样的应用来说,放到处理器的B组去跑才是更优选。而相对的,如果有一个应用,堆了更大的V-Cache能够带来cache命中率提升,或者对核心频率反倒没那么敏感,则这样的应用放在A组跑会更好。实际上,A组5.2GHz核心频率、B组5.7GHz核心频率,加上两者缓存容量不同是能够带来不同应用跑在不同核心簇上的性能差异的。另外值得一提的是,AMD此前在发布这一代V-Cache产品时就提到,正与微软合作,就操作系统层面做优化。这里的优化应该就涉及到粗粒度的调度问题了,就是不同的游戏可以跑在不同的核心簇上——虽然可能现阶段也仅限于某些应用类型。Chips and Cheese也在评论中提到,核心间不一致的性能体现,似乎是现在的某种趋势——用不同的核心配置来覆盖不同的应用场景。即便可能对V-Cache而言,AMD主观上并不想带来这样的结果,但实际也真的造成了这样的结果。换句话说,如果某个非存储敏感型应用跑在了A组核心上,则其性能表现就无法达到理想水平。虽然就AMD的架构设计来说,这方面的影响或许远不及Intel的大小核设计,在调度不佳时带来的影响如此巨大。最后我们借用Chips and Cheese的测试数据,来看看V-Cache在这一代处理器产品中的真实性能表现。就这组数据来看,我们认为V-Cache带来的延迟增加,实则远没有我们想象得那么严重——所以总体结果都算是相当理想。对比的两个主要对象,实际上就是前文提到的A组(蓝线)和B组(橙线)核心簇。也就是AMD Ryzen 7950X3D的其中叠了V-Cache的8个核心,和没有叠V-Cache的8个核心的比较。Zen 4架构的V-Cache的确带来了一定程度的延迟惩罚。A组核心相比于B组,从L3取数据需要额外4个周期。而且需要指出的是,从延迟时间来看,因为A组的频率本来就低,实际的延迟影响会更大一些;不过+1.61ns的延迟,换3倍容量增加也还是值得的。带宽方面,单核占用L3带宽,B组相比A组有11%的带宽优势——这应该主要是频率差异造成的。如果用上所有的核心去取数据,则全核最高频率当然都会下降——下降以后,A组频率仍然低于B组,所以全核L3 cache带宽表现仍然是B组更好——不过此时的带宽差异,已经大于频率差异。若限定到相同频率(上图),则A组达成的L3带宽好像的确略弱于B组。Chips and Cheese得到的数据是,A组核心簇,平均每个核心每周期18.45 bytes数据;B组的这个值是20.8 bytes。我们感觉,理论上应该不会有这方面的差异才对,造成差异的原因未知。另外在缓存命中率方面,Chips and Cheese测了几个游戏,包括《GHPC》《赛博朋克2077》《数字战斗模拟世界(DCS)》和《使命召唤:黑色行动冷战》。这里我们只做一些数据总结,具体的测试和数据,感兴趣的同学可以去看看原文。在《GHPC》游戏中,V-Cache能够带来33%的L3 cache命中率提升,达成平均78%的平均命中率——也就彻底抵消了那点延迟增加。则最终在GHPC游戏里,A组相比于B组核心,有着9.67%的IPC提升——还挺理想的吧。《赛博朋克2077》游戏的测试结果则显示了A组比B组有13.4%的IPC领先(上图)——我们日常说一代CPU架构演进,平均也就带来这个幅度的IPC提升,就已经相当成功。而在《DCS》这个原本L3命中率就已经比较高的游戏里,V-Cache获得的收益也非常有限——反而是延迟增加,成为游戏帧率负加成的一大因素。所以《DCS》算是个V-Cache实际效果中的反例。《使命召唤:黑色行动冷战》这个游戏原本的L3命中率平均就低于50%,于是在增加V-Cache之后命中率大增了47%,最终纸面上就有了19%的IPC提升。Chips and Cheese针对这个游戏做了更深入的分析,发现V-Cache显著减轻了处理管线中的后端(Backend)压力占比,也就是执行单元因为缓存命中率的增加而更大程度地提高了效率;但对前端性能产生了少许影响。最后,Chips and Cheese也对比了视频编码和文件压缩场景。在libx264视频编码测试里,命中率提升了16.75%,IPC有大约4.9%的提升——但考虑一下B组核心频率高了7%,最终A组的性能也就没有优势可言了。其实libx264这个测试也很好地反映了,为什么AMD要用A、B两组不同的核心,或者说仅有一个CCD堆V-Cache。因为更高的核心频率,在大量应用场景还是能够提供更好的性能表现。7-Zip文件压缩测试,V-Cache带来了将近30%的缓存命中率提升,IPC提升幅度9.75%。考虑B组核心频率9%的优势通常在性能表现上不会是线性的,这个测试还是能够体现在一些非游戏负载中,V-Cache带来的价值的。不过似乎AMD的默认策略,就是把非游戏类的应用放到不带V-Cache的CCD上去跑,这好像就让AMD率先感受了一把“异构”带来的调度问题...其实这篇文章主要还是期望去谈V-Cache带来的价值,并没有我们此前想象得那么有限——虽然die size的代价仍然需要考虑。第一部分聊14代酷睿可能要采用的L4 cache只是附带罢了。而且我们目前掌握14代酷睿的情报毕竟还是有限,不知道L4 cache实际真正带来的收益有多大,以及具体是怎么做的。但可以肯定的是,未来的AMD客户端处理器仍然会坚持采用V-Cache方案。只是不知道在应对性能开始表现出差异的不同核心,AMD会不会有其他方面更进一步的思考。而即便只是V-Cache这种看来只是CPU缓存的技术变化,实则也能看出针对不同类型的应用,做特别优化的必要性(虽然可能V-Cache只是服务器端技术的副产品...)。
[ 新闻来源:电子工程专辑,更多精彩资讯请下载icspec App。如对本稿件有异议,请联系微信客服specltkj]
全部评论

相关文章
热门搜索
高通进军数据中心市场
海光信息合并中科曙光
华为
台积电
中芯国际
联发科
高通
英特尔
芯片











 分享至微信
分享至微信