



解读RIFFA驱动
基于Linux
导言
去年便计划给大家出个关于PCIe驱动的文章,因为种种原因没能继续写,本次发一个关于RIFFA驱动的系列文章,文章很长,本系列一共23259个字,文章来源西安电子科技大学锤王。
感谢西安电子科技大学锤王投稿,文章版权归原作者
**目录**
第一章RIFFA仓库地址
第二章体系结构概述
2.1冯·诺依曼结构和哈佛结构
2.2现代计算机执行过程概述
2.3Linux启动过程概述
2.4用户态和内核态
2.5CPU访存过程概述
2.6高速缓存概述
2.7中断概述[9]
2.7.1单片机中断系统
2.7.2MPU中断系统
2.7.3Linux中断映射简述
2.8指令集概述
第三章字符设备驱动框架
3.1Linux设备分类
3.2设备号
3.3字符设备操作函数结构体
3.5注册字符设备
3.6驱动在Linux中的表现形式
3.7自动创建设备节点
3.8模块插入/卸载函数的关联
第四章PCI设备驱动框架
4.1pci_dev结构体
4.2PCI设备驱动的ID号设置
4.3probe函数和它的执行条件
4.4pci_driver结构体
4.5PCI驱动在init函数中要做的事
4.6PCI驱动初始化流程
第五章Linux并发与竞态概述
5.1并发与竞争
5.2原子操作
5.3自旋锁
5.3.1自旋锁的优缺点
5.3.2自旋锁的死锁
5.4信号量
5.4.1信号量
5.4.2读写信号量
5.5互斥体
第六章Linux中断处理与阻塞I/O概述
6.1Linux中断处理
6.1.1中断服务函数的主旨
6.1.2中断上下文
6.2阻塞I/O
6.2.1阻塞I/O与非阻塞I/O
6.2.2等待队列简介
6.2.3等待队列头和等待队列项
6.2.4将队列项添加/移除等待队列头
6.2.5休眠与唤醒
第七章Linux内存管理与DMA映射概述
7.1进程地址空间布局
7.2页表概述
7.3kmalloc和vmalloc概述
7.4缺页中断概述
7.5DMA的类型
7.6一致性DMA和流式DMA
7.7Linux中建立一致性DMA
7.8Linux中建立SGDMA
7.8.1SG缓冲区的组织形式
7.8.2SG缓冲区的建立流程
第八章RIFFA驱动分析
8.1RIFFA驱动文件构成
8.2RIFFA驱动的消息队列
8.3RIFFA驱动创建字符设备
8.4RIFFA驱动初始化收发通道
8.5RIFFA驱动的probe函数
8.6RIFFA驱动的中断回调函数
8.7RIFFA驱动建立SG缓冲区
8.8RIFFA驱动读通道函数
8.9RIFFA驱动写通道函数
8.10RIFFA驱动ioctl函数
Part1
RIFFA是一个用于PCIe设备的可重用集成框架,它的Github仓库如下:
https://github.com/KastnerRG/riffa.git
本文档旨在从基本概念开始逐步剖析RIFFA项目中基于Linux的驱动程序。
Part2
12.1 冯·诺依曼结构和哈佛结构
计算机体系中有两种耳熟能详的基本结构,冯·诺依曼结构和哈佛结构。
冯·诺依曼结构的基本思想是将数据存储和程序存储都使用一块存储器来完成,不过缺点是可能会产生结构冒险,即CPU执行一些程序时需要从程序存储器中获取指令,同时也需要从数据存储器中获取数据,但存储器是共用的,每次只能取到一种数据,这就产生了结构冒险。
哈佛结构将数据和程序分别用两个存储器来存储,这样就解决了结构冒险,但缺点是需要两块存储器,成本提高了。
22.2 现代计算机执行过程概述
现代处理器一般使用混合结构,外部使用同一个存储器存储数据段和代码段(内存条),内部将数据和代码分开成两个存储器存储(I-Cache和D-Cache)。
现代计算机一般都有内存、硬盘这两种存储器。硬盘主要存储文件,当需要执行某个程序时,CPU会把该文件读到内存中运行,此时内存就是那个共用的主存储器,CPU访存时若Cache未命中,就会将代码和数据分别加载到I-Cache和D-Cache上然后运行。
32.3 Linux启动过程概述
以ARM为例,在一个运行着Linux的设备中,硬盘上主要存储着Linux内核镜像、根文件系统和设备树文件。在设备上电时首先会从硬盘读取u-boot运行,u-boot是一种bootloader程序,负责完成必要设备的初始化(比如DDR、PLL等)、堆栈的初始化、读取设备树的dtb文件并存入内存,并将启动参数传递给Linux内核(其中就包括dtb文件在内存中的地址,后面Linux可以通过这个地址找到设备树),引导Linux启动,u-boot寿命结束后就会从硬盘中读取内核镜像并依据u-boot传递的参数启动。
而X86的这一启动过程由主板上的BIOS芯片完成,X86没有设备树文件,设备的枚举也由BIOS完成(包括PCI设备)。
42.4 用户态和内核态
现代大型操作系统一般都分为内核态和用户态,用户态是指用户可以操作到的空间,比如在Ubuntu中使用终端、编写C语言应用程序等我们看得到的操作均是在用户态下运行的。内核态是对用户不透明的,用户无法直接操作内核空间的事物。
之所以将系统分为用户态和内核态,是因为内核态可以直接操作外设及内存,而些操作对于用户来说是非常危险的操作。在大部分CPU体系中,均将指令集划分了一些特权级别,比如Cortex-A9将工作模式分为如下几种:
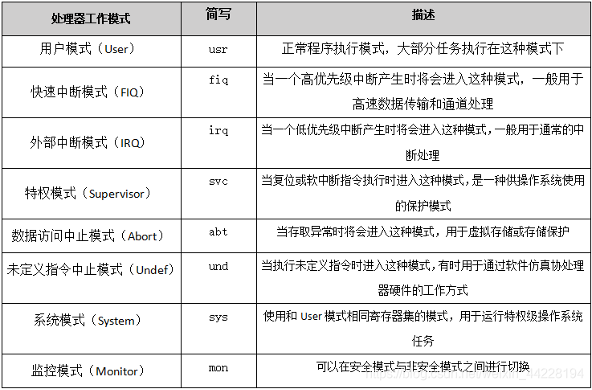
可以看到,大部分用户操作均在用户模式下进行,而复位、软中断等操作需要在特权模式下进行,这种模式供操作系统使用。如果允许用户随意使用特权指令,可能会带来意想不到的灾难性后果,比如用户可以使用内存清除指令清除内存空间进而导致系统崩溃。
所以需要将用户和内核划分开来,当然用户态也需要能够切换到内核态,毕竟用户想要操作什么东西都需要执行驱动程序或是调用内核来完成。从用户态切换到内核态一般通过系统调用和中断,系统调用就是指在用户态应用程序中调用操作系统提供的接口(比如open、close函数),系统调用属于一种软中断,软中断会导致CPU陷入内核;同样,中断也会让CPU陷入内核来执行中断回调函数。
这些特权级别切换在CPU级别都是有对应的汇编指令的,执行汇编指令即可完成切换,当然这些汇编程序都是已经内嵌到Linux内核源码中的,切换过程用户不必关心。
52.5 CPU访存过程概述
CPU访存过程的概念图如下所示:
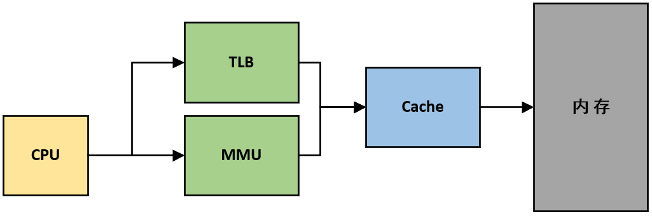
MMU(内存管理单元)的作用是进行虚拟地址和物理地址间的映射,记录映射结果的组织结构叫做页表(Page),这个将在后面Linux内存管理中讲述。
TLB(转址旁路缓存)的作用类似于Cache,但是配合MMU使用的,其作用是当CPU访问MMU前首先会访问TLB,如果TLB中没有存储对应的页表项,则再访问MMU,加这样一个TLB的目的就是因为访问页表太慢了,尤其现代操作系统中都是多级页表(Linux页表为3~5级)。
所以当CPU想要访问内存时,首先将虚拟地址(由页号和页内偏移构成)传递给TLB,若TLB命中,则将其中存储的对应的物理页号传递给Cache;若TLB未命中,则访问该进程的页表,获取到对应的物理页号再传递给Cache。
关于虚拟地址的构成将在Linux内存管理中描述。
62.6 高速缓存概述
Cache(高速缓存)在多核处理器中的组织形式如下图所示:
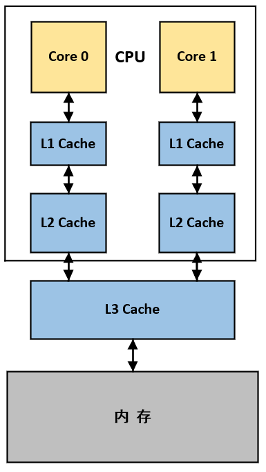
现代处理器一般分为三级缓存,L1~L3缓存容量逐步变大,L1和L2都是和Core绑定的,L3是多核共享的。缓存越小,地址解码越快,读写速度也就越快,但容量低也意味着容易未命中,当L1未命中时会读取L2,L2失效会读取L3,若所有Cache均失效则访存。这种多层次存储结构的好处是能够减小Cache未命中而访问内存所带来的较大代价。
Cache的组织形式分为直接映射、组相联映射和全相联映射,读写的单元是Cache line;
Cache的写策略分为写直通、写缓存、写返回等,广泛使用的是写返回策略,这里就不展开讲了。
72.7 中断概述
2.7.1 单片机中断系统
单片机的中断较为简易,以Cortex-M系列为例,其中断控制器名为NVIC,负责使能中断、设置中断优先级、中断仲裁等。
单片机在汇编启动文件中维护了一张中断向量表,中断向量表在链接的起始地址处,也就是单片机执行代码首先要执行中断向量表。需要注意的是,中断向量表不是一个像表格似的文件,它就是一段汇编程序,映射了中断号和中断服务函数的入口地址而已。
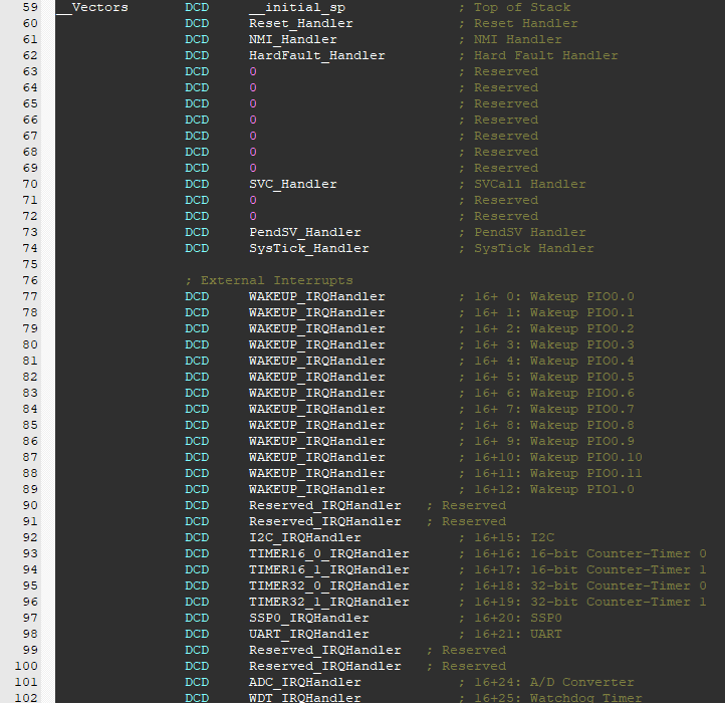
下面看一下恩智浦公司的LPC1114芯片的中断向量表,它是Cortex-M0内核的:
单片机执行代码首先就执行中断向量表的第一句,这里是设置sp指针(堆栈),然后跳转到复位中断的服务函数Reset_Handler,在里面执行一些初始化操作然后调用C语言的main( )函数,从此进入C语言执行环境。
中断向量表是按顺序排的,这个大体顺序是ARM公司定好的,外设中断部分的顺序是SoC公司定好的,规则就是按中断号由小到大排列,当发生一个外设中断时,可通过中断号找到中断向量的地址,而中断向量本身又是中断服务函数的入口地址,进而执行中断服务函数。
可以看到,在单片机里,每个外设都是有中断向量的,因为单片机的中断比较少。也就是每个外设中断都对应一个中断服务函数,而不需要查看是什么外设的中断。
2.7.2 MPU中断系统
而在MPU(微处理器)中就与上面不太一样了,以Cortex-A7为例,先介绍一下GIC(通用中断控制器)。
GIC结构框图如下所示:左侧是中断源输入,右侧是给Core发送的中断信号。
SPI(共享中断),共享是指所有Core共享的中断,外部中断都属于共享中断,例如GPIO、UART中断等。
PPI(私有中断),私有中断就是Core独有的,因为每个Core肯定有自己的中断。
SGI(软件中断),由软件触发引起的中断,通过向寄存器GICD_SGIR 写入数据来触发,系统会使用 SGI 中断来完成多核之间的通信。
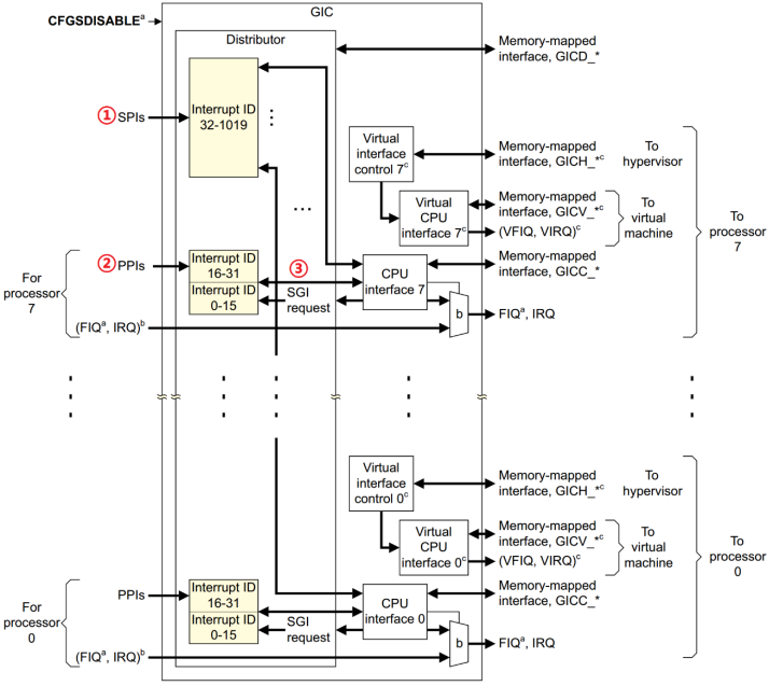
GIC分为两个逻辑块,Distributor和CPU Interface。
Distributor负责处理各个中断事件的分发问题,也就是中断事件应该发送到哪个 CPU Interface 上去。分发器收集所有的中断源,可以控制每个中断的优先级,它总是将优先级最高的中断事件发送到 CPU 接口端,并将其他中断信号挂起并缓存起来等待下次发送。
CPU Interface和Core连接,主要负责发送优先级最高的那个中断通知CPU、CPU通知GIC中断处理完成、和CPU进行一些交互等。最终GIC通过4根线通知CPU有中断:VFIQ、VIRQ、FIQ、IRQ;带V的都是和虚拟化相关的,FIQ是快速中断,IRQ才是平时用的最多的中断线。
Cortex-A7也有中断向量表,不过可不像单片机一样好几十行,Cortex-A7只有8个中断向量,如下表所示:
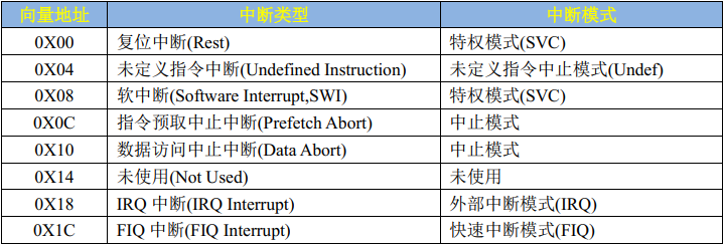
因为MPU的中断太多了,Cortex-A7的GIC-v2可是支持1020个中断。介绍一下常用的:
软中断:由SWI指令引起的中断,Linux的系统调用会用SWI指令来引起软中断,通过软中断来陷入到内核空间。
复位中断:CPU复位以后就会进入复位中断,可以在复位中断服务函数里面做一些初始化工作,比如初始化SP 指针、DDR等。
IRQ:外部中断,外设的中断经过GIC仲裁后都走这一条线。
MPU的中断向量表依然是放在链接地址开头处,上电执行复位中断,然后进入main( )函数。如果此时有一个外设中断通过GIC的仲裁由IRQ线通知CPU,那么CPU会跳转到链接地址+0x18处访问IRQ中断向量,然后由中断向量跳转到IRQ中断服务函数中,因为外设都走的是共享中断,通知CPU只有一条IRQ线,所以进入中断服务函数首先要做的就是判断是什么中断,这就需要CPU去读取GIC的一个寄存器,这个寄存器里存这当前从IRQ送出去的中断的中断号,根据中断号就知道是什么中断了。
2.7.3 Linux中断映射简述
上面说的中断号都是hwirq(硬件中断号),这些中断号是和硬件相关的,是不能改变的,而Linux中的所谓中断号(irq)是虚拟的,是和硬件没关系的。这么做主要是因为现在的大型SoC里面可能不止一个中断控制器,多个中断控制器间可能有中断号的冲突,Linux为了区分是哪个中断控制器的哪个中断,就将它们映射为虚拟中断号了。
82.8 指令集概述
指令集常见的包括ARM、RISC-V、MIPS、8051、X86等。
指令集再细分出指令集架构(ISA),比如X86中的i386、i686;ARM中的ARMv7、Thumb;RISC-V中的RV32-I、RV64-IA等,ISA是具体的指令、ABI(二进制接口)、内存划分等细节性规定的集合。
本文档将使用ARM和X86作为例子讲述。
