


随着深度学习逐步成熟化规模化,人工智能技术从“感知智能”向“认知智能”迈进。AI除了“看到”或“听到”,开始初步逐步具备像人类一样的思考能力。多模态融合、3D视觉智能技术、自动机器学习等正在成为人工智能领域的关键研-究热点。
当地时间6月21日,电气与电子工程师协会(IEEE)国际计算机视觉与模式识别会议CVPR (Conference on Computer Vision and Pattern Recognition)2022在美国新奥尔良开幕。这是疫情之后,首次恢复线下参会,线下注册参会的人数达到5641人,甚至超过2017年。
6月23日,CVPR 2022落下帷幕。值得一提的是,今年CVPR大会特设了缅怀近期因病去世的青年AI科学家孙剑的环节,现场播放了一段由孙剑的亲友及同事们所制作的纪念视频。视频播放结束后,现场持续了十几秒的掌声。
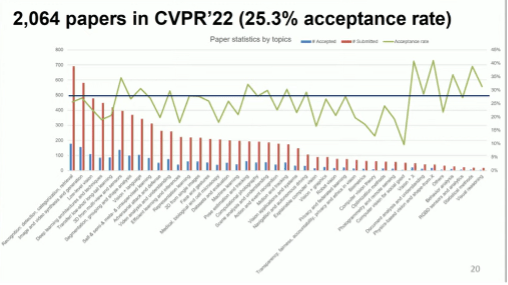
据程序主席华刚(Gang Hua)介绍,本次会议共收到了来自23389名作者共8161篇投稿,相比2021年的7093篇增长15%。其中,来自中国大陆的作者投稿数最多(44.59%),美国以占比20.65%位列第二。本届共接收了2064篇论文,接收率为25.3%,其中有342份被选为Oral论文,1721份被选为Poster论文。

Long Quan,上排右二;Gang Hua,下排左二本届大会共有两位华人主席,分别是主席权龙(Long Quan)与程序主席华刚(Gang Hua)
黄煦涛纪念奖期间,现场回忆孙剑
黄煦涛纪念奖(Thomas Huang Memorial Award)以计算机视觉领域泰斗黄煦涛命名,PAMITC 奖励委员会2021年批准设立该奖,是为了表彰在计算机视觉领域长期作出贡献、研究和指导的杰出人士。该奖项每年颁发给博士毕业后至少7年的研究人员,最好是职业生涯中期(博士毕业不能超过25年)。该奖的候选人考虑CV领域的所有研究人员,奖励包括3000美元现金和一块奖牌。

CVPR 2022黄煦涛纪念奖由知名华裔女科学家、斯坦福大学计算机科学系首任红杉教授李飞飞获得。

李飞飞为斯坦福大学计算机科学教授,美国工程院院士,美国国家医学院院士。她的专业领域是计算机视觉和认知神经科学。2016 年,李飞飞加入 Google 云端人工智能暨机器学习的中国中心团队,以 Google Cloud 首席科学家身份任团队负责人之一。2018 年 9 月,她宣布返回斯坦福大学任教,并持续参与斯坦福大学的 AI 议题研究。
李飞飞的工作包括括受认知启发的 AI,机器学习,深度学习,计算机视觉和 AI + 医疗保健,尤其是用于医疗保健交付的环境智能系统。她还从事认知和计算神经科学方面的工作。她发明了 ImageNet 和 ImageNet Challenge,其中 ImageNet Challenge 是一项重要的大规模数据集和基准测试工作。
她在 Google Scholar 上的论文被引量达到 167561,h 指数为 128。
提到黄煦涛先生,不由让人想到计算机界流传的“中国计算机视觉40年传承”。
“16年前,黄煦涛去香港过圣诞,无意间发现一同聚会的几位计算机视觉的领军人物均相差10岁,分别是:1936年出生的黄煦涛、1946年出生的马颂德、1956年出生的高文、1966年出生的沈向洋。大家便讨论下一次聚会,是否能再找到另一位再年轻10岁的计算机视觉领军人物,讨论迅速指向同一个人,那便是沈向洋的学生、1976年出生的孙剑。”香港理工大学教授陈长汶在2020年的全球人工智能与机器人大会(GAIR) “Thomas S. Huang纪念专场—中国计算机视觉的40年传承”中谈道。
孙剑于大会前夕的离世让人惋惜,出自他的学生、好友的纪念文章现在依然可以看到很多。

孙剑此前曾两次获CVPR最佳论文奖,据程序主席华刚在会上介绍,“作为CV领域的知名学者,孙剑博士研究成果硕果累累。”Google Scholar数据显示,孙剑的论文引用量达到28万6千余次,h-index为121。
如果要说出孙剑博士的三篇论文代表作,那么华刚认为第一篇应该是“Stereo matching using belief propagation”。第二篇则是他带领团队完成的“去雾”论文“Single Image Haze Removal Using Dark Channel Prior”,这也是亚洲第一篇获得CVPR最佳论文奖的论文。
第三篇则是“Deep Residual Learning for Image Recognition”,这篇是与何恺明等团队成员携手创造出的残差网络ResNet,是孙剑最为人所熟知的工作,也是孙剑所有论文中引用量排名第一的。在2015年提出之后,ResNet拿下了ImageNet冠军,并获得了CVPR 2016最佳论文奖。
ResNet是世界上第一个超过百层的深度神经网络,也是深度学习领域最重要的研究之一。残差神经网络的主要贡献是发现了“退化现象(Degradation)”,并针对退化现象发明了 “快捷连接(Shortcut connection)”,极大地消除了深度过大的神经网络训练困难问题。正是由于ResNet,神经网络的深度首次突破百层、最大的神经网络甚至超过了1000层。
2022年的最佳论文奖

今年,获得CVPR最佳论文奖的是苏黎世联邦理工学院(ETH Zurich)、华盛顿大学、佐治亚理工学院、捷克理工大学合作的《Learning to Solve Hard Minimal Problems》。论文地址:https://arxiv.org/abs/2112.03424

论文摘要:该研究提出了一种在 RANSAC 框架中解决困难的几何优化问题的方法。最小化问题源于将原始几何优化问题松弛化(relax)为具有许多虚假解决方案的最小问题。该研究提出的方法避免了计算大量虚假解决方案。研究者设计了一种学习策略,用于选择初始问题 - 解决方案对以用数值方法继续解决原问题。该研究通过创建一个 RANSAC 求解器来演示所提方法,该求解器通过使用每个视图中的 4 个点进行最小松弛化来计算 3 个校准相机的相对位姿。平均而言,该方法可以在 70 μs 内解决一个原始问题。此外,该研究还针对校准相机的相对位姿这一问题进行了基准测试和研究。
2022年的最佳论文奖——最佳论文荣誉提名

来自卡内基梅隆大学(CMU)团队的《Dual-Shutter Optical Vibration Sensing》获得最佳论文荣誉提名。论文地址:https://openaccess.thecvf.com/content/CVPR2022/papers/Sheinin_Dual-Shutter_Optical_Vibration_Sensing_CVPR_2022_paper.pdf
论文摘要:视觉振动测量是一种非常有用的工具,可用于远程捕捉音频、材料物理属性、人体心率等。虽然视觉上可观察的振动可以通过高速相机直接捕捉,但通过将激光束照射振动表面所产生的散斑图案的位移成像,可以从光学上放大微小且不易察觉的物体振动。
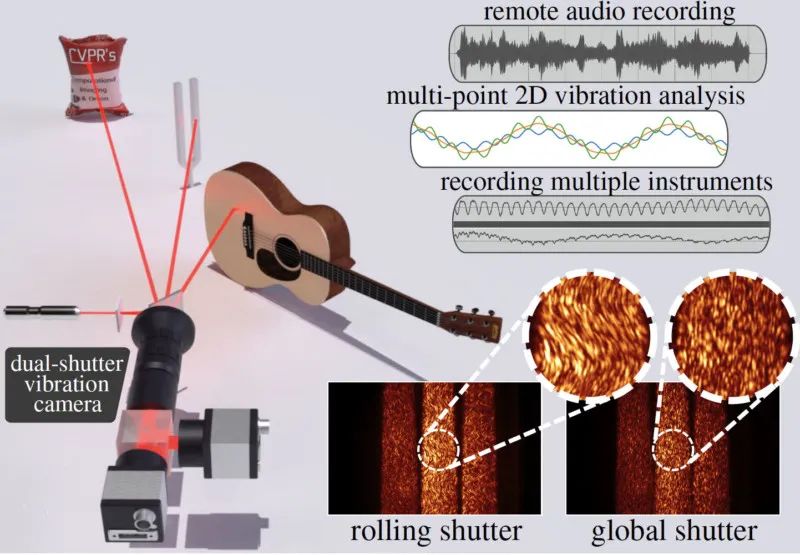
在本文中,研究者提出了一种在高速(高达 63kHz)下同时检测多个场景源振动的新方法,该方法使用了额定工作频率仅为 130Hz 的传感器。他们的方法使用两个分别配备滚动和全局快门传感器的相机来同时捕捉场景,其中滚动快门相机捕捉到对高速物体振动进行编码的失真散斑图像,全局快门相机捕捉散斑图案的未失真参考图像,从而有助于对源振动进行解码。最后,研究者通过捕捉音频源(如扬声器、人声和乐器)引起的振动并分析音叉的振动模式,展示了他们的方法。
2022年的最佳论文奖————最佳学生论文
来自同济大学、阿里巴巴合作的《EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation》获得最佳学生论文,可以注意到这篇论文全部由华人作者合作完成。论文地址:https://openaccess.thecvf.com/content/CVPR2022/papers/Chen_EPro-PnP_Generalized_End-to-End_Probabilistic_Perspective-N-Points_for_Monocular_Object_Pose_Estimation_CVPR_2022_paper.pdf

该论文的第一作者为同济大学汽车学院智能汽车研究所、上海自主智能无人系统科学中心2020级硕士研究生陈涵晟,其导师为熊璐教授,论文的通讯作者为副导师、同济大学汽车学院助理教授田炜,阿里巴巴王丕超博士。这也是CVPR自2001年设立最佳学生论文奖以来,获奖论文的第一作者首次来自中国高校。
论文摘要:利用透视点(PnP)基数从单个 RGB 图像中定位 3D 物体是计算机视觉领域一个长期存在的问题。在端到端深度学习的驱动下,近期的研究建议将 PnP 解释为一个可微分层,如此 2D-3D 点对应就可以部分地通过反向传播梯度 w.r.t. 物体姿态来学习。然而,从零开始学习整套不受限的 2D-3D 点在现有的方法下很难收敛,因为确定性的姿态本质上是不可微的。

这篇论文提出了一种用于普遍端到端姿态估计的概率 PnP 层——EPro-PnP(end-to-end probabilistic PnP),它在 SE 流形上输出姿态的分布,实质地将分类 Softmax 带入连续域。2D-3D 坐标和相应的权值作为中间变量,通过最小化预测姿态与目标姿态分布之间的 KL 散度来学习。其基本原理统一了现有的方法,类似于注意力机制。EPro-PnP 的性能明显优于其他基准,缩小了基于 PnP 的方法与基于 LineMOD 6DoF 的姿态估计以及 nuScenes 3D 目标检测基准的特定任务方法之间的差距。
2022年的最佳论文奖——最佳学生论文荣誉提名
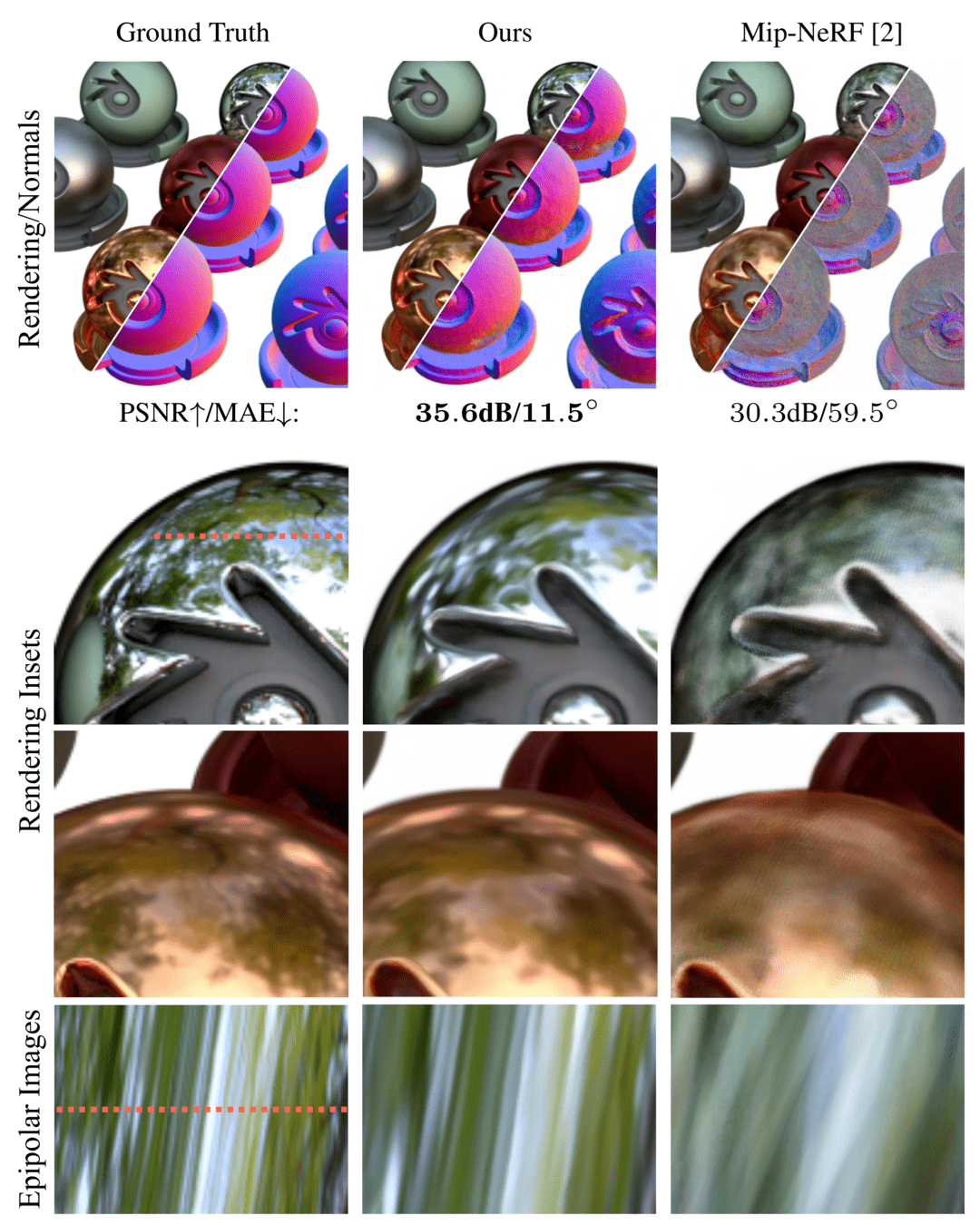
哈佛大学、谷歌研究院合作的《Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields》则获最佳学生论文荣誉提名。 论文地址:https://arxiv.org/pdf/2112.03907.pdf

论文摘要:神经辐射场是一种流行的视图合成技术,它将场景表示为连续的体积函数,由多层感知器参数化,多层感知器提供每个位置的体积密度和与视图相关的散发辐射。虽然基于 NeRF 的方法擅长表征平滑变化的外观几何结构,但它们通常无法准确捕捉和再现光泽表面的外观。该研究提出了 Ref-NeRF 来解决这个问题,它将 NeRF 与视图相关的散发辐射的参数化替换为反射辐射的表征,并使用空间变化的场景属性的集合来构造该函数。该研究表明,使用法向量上的正则化器,新模型显著提高了镜面反射的真实性和准确性。此外,该研究还表明该模型对散发辐射的内部表征是可解释的,这对于场景编辑非常有用。
其他奖项
Longuet-Higgins 奖
Longuet-Higgins 奖是 IEEE 计算机协会模式分析与机器智能(PAMI)技术委员会在每年的 CVPR 颁发的「计算机视觉基础贡献奖」,表彰十年前对计算机视觉研究产生了重大影响的 CVPR 论文。该奖项以理论化学家和认知科学家 H. Christopher Longuet-Higgins 命名。
今年的获奖论文为 2012 年发表的《Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite》,当时三位作者中的 Andreas Geiger 和 Philip Lenz 来自卡尔斯鲁厄理工学院, Raquel Urtasun 来自丰田工业大学芝加哥分校。
论文地址:http://www.cvlibs.net/publications/Geiger2012CVPR.pdf
在本文中,研究者利用他们自己的自动驾驶平台为立体、光流、视觉测程 / SLAM 和 3D 目标检测等任务开发了一个新的具有挑战性的基准。他们的记录平台配备了 4 台高分辨率摄像机、1 台 Velodyne 激光扫描仪和 1 个 SOTA 定位系统,基准则包括 389 个立体和光流图像对、39.2km 长的立体视觉测程序列以及在杂乱场景中捕获的超过 20 万个 3D 目标注释(每张图像最多可见 15 辆车和 30 名行人)。

左上为配备了传感器的记录平台,中上为来自研究者视觉测程基准中的轨迹、右上为视差和光流图、下方为 3D 目标标签。
青年研究者奖
青年研究者奖(Young Researcher Awards)旨在表彰年轻的科学家,鼓励 ta 们继续做出开创性的工作。评选标准是获奖者获得博士学位的年限少于 7 年。今年的奖项由康奈尔大学计算机科学系的助理教授Bharath Hariharan和普林斯顿大学计算机科学系的助理教授Olga Russakovsky获得。

Bharath Hariharan从事计算机视觉和机器学习方面的工作,尤其是那些无视大数据标签的重要问题。Hariharan 主要研究方向为将机器学习的进步与计算机视觉、几何和特定领域知识的见解结合起来。
目前,Hariharan 所在团队正在致力于构建一个系统,该系统可以在很少或没有监督的情况下了解数以万计的视觉概念,产生丰富而详细的输出,比如精确的 3D 形状,并对世界进行推理,将这种推理传递给人类。
他在 Google Scholar 上的论文被引量达到 25242,h 指数为 38。
个人主页:http://home.bharathh.info/
Olga Russakovsky致力于开发能够对视觉世界进行推理的人工智能系统。Russakovsky 主要研究方向为计算机视觉、人机交互等领域。她的多篇论文被 ECCV、CVPR 等接收。
她在 Google Scholar 上的论文被引量达到 34756,h 指数为 25。
个人主页:https://www.cs.princeton.edu/~olgarus/
商汤、OPPO等厂商多篇论文入选
中国厂商方面,商汤科技及联合实验室共71篇论文入选本届CVPR,再创新高,其中有接近四分之一被录用为Oral(口头报告),涵盖三维视觉、自动驾驶等多个备受关注的前沿研究领域和方向,继续巩固在全球计算机视觉研究领域的领跑势头。
OPPO有七篇论文成功入选,涵盖多模态信息交互、三维人体重建、个性化图像美学评价、知识蒸馏等多个研究领域。
腾讯优图实验室30篇论文入选,含场景文本语义识别等领域;来自字节跳动智能创作团队的 12 篇论文入选,包含 1 篇 Oral;旷视研究院 17 篇,飞步科技有3篇,爱奇艺AI团队1篇。华为、百度、腾讯、阿里等视觉大厂,也有论文入围。
此外,西安电子科技大学、西北工业大学、南京大学、天津大学、深圳市大数据研究院等高校和机构也有多篇论文入选。
本文内容参考澎湃新闻、同济大学新闻中心、OPPO新闻、机器之心、商汤新闻报道


