



今年中国(上海)集成电路创新峰会的排场相当大,列席的中国科学院和工程院院士就有5个,外加重磅级的企业和政府机构代表。本次峰会有个存储技术论坛,除了包括展锐、东芯半导体、英韧科技、江波龙电子、北京得瑞领新等在内的企业代表所做的主题演讲,有个相关存储前沿技术且相当有干货的主旨报告,来自中国科学院院士、复旦大学芯片与系统前沿技术科学院院长刘明。
所以我们想特别用一篇文章的篇幅来呈现刘明院士的演讲,期望对想要了解存储前沿技术的各位有帮助,可作为对当前存储技术深入的索引。实际上,今年WAIC世界人工智能大会的芯片论坛上,刘明院士就有做过近存与内存计算的研究报告,此前我们也做了报道;本文将对这部分内容有了进一步的延伸。

有关本次技术论坛的其他企业代表演讲内容,我们还将另外撰文。
今年的Aspencore双峰会上,深圳佰维存储科技股份有限公司CEO何瀚曾经从较高抽象层总结过看待存储技术的大方向,及其对应的演进方向,有兴趣的读者可前往阅读。刘明院士的分享,是从存储介质方面所做的技术探讨。
从存储介质的角度来看,易失性和非易失性存储器是两个大类。比如DRAM、NAND等都是很多读者耳熟能详的。若期望存储器有着较长的数据保持时间,那么potential well(势阱)barrier就要高;如果要求处理速度快,则barrier就需要低。所以存储器的处理和存储性能很难做同步优化。“这是这类存储器本身的物理局限性决定的。”刘明说。
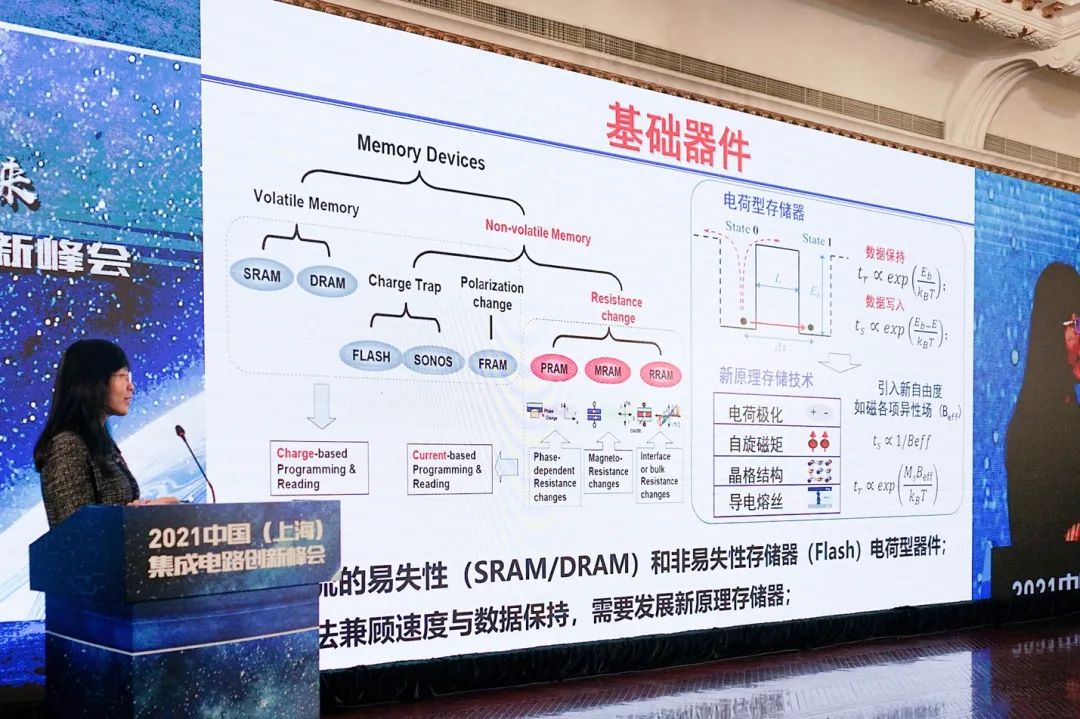
这也是新型存储器出现的原因,“所有的新型存储器都引入了新的物理量,有望分别来优化这两个特性。”在我们所知当前主流的存储器面临挑战的同时,新型存储就有了发展的机会——比如上图中的MRAM、RRAM。
从大方向来看,我们都知道如今的“主流存储器通过新材料+架构+三维集成”继续实现快速发展,以期不断提高性能并降低成本。但刘明强调,即便如此主流存储器依然无法满足市场快速增长的需求。
与此同时,新型存储器的性能有了发展的机会,但它们暂时很难在工程问题的解决,以及成本方面与主流存储器相较。不过当前的新型存储器已经有了对应的发展,比如说嵌入市场对于RRAM的应用。
那么本文也按照刘明院士的报告架构,分成两个部分,分别谈主流存储器面临的挑战及其发展(DRAM与3D NAND);以及新型存储器的技术现状。
DRAM现在发展成什么样了?
对存储器而言,追求的始终是更快的速度、更低的功耗和更高的存储密度。在器件尺寸scaling down的大前提下,存储容量不能变小,发展过程中就会面临很多挑战。此处刘明谈到了DRAM选通管与电容技术的演进。主要如下面两张图所示:
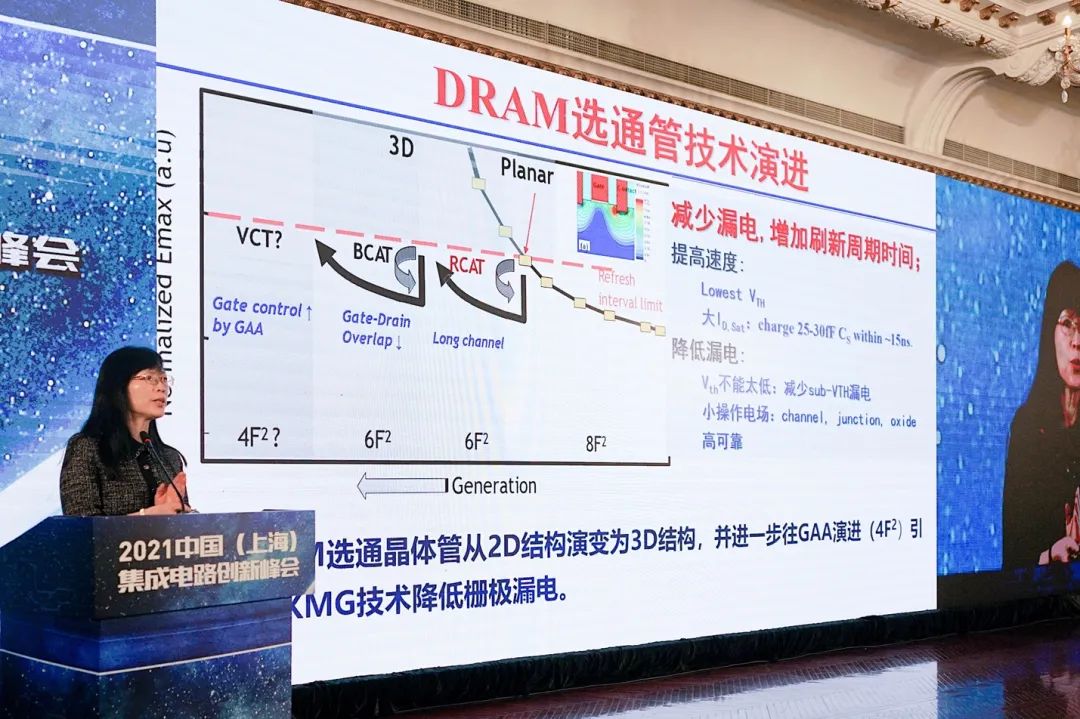
“选通管技术,很大程度借鉴了logic器件的发展,就要减少漏电。DRAM刷新占到了很大的功耗比重,漏电小了才能增加刷新周期的时间。”
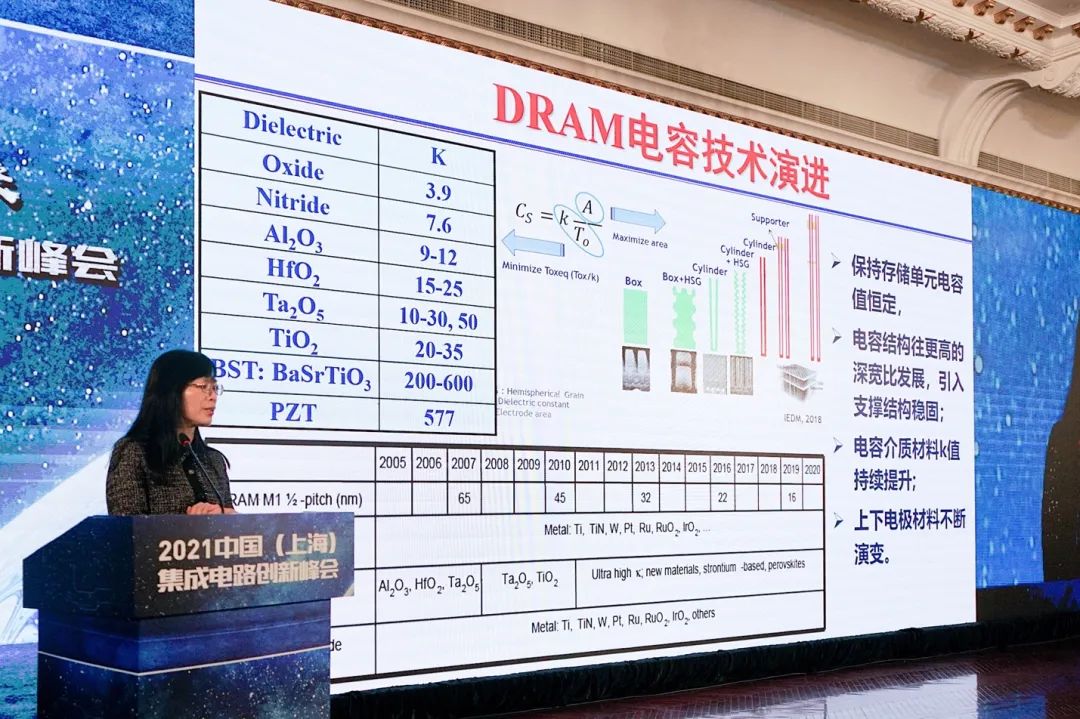
对于电容来说,是“更具挑战性的事情”。从PPT中列出的公式可知,“如果想要维持电容器的电容量不变,或者增大的话,面积就要增大。但DRAM走的是尺寸微缩的道路,这其中就存在矛盾。为了维持电容量不变,有很多工作要去做,包括各种空间结构的变化。在较高空间结构的情况下,还需要考虑支撑结构问题。”
“除了结构变化之外,还有材料的变化。无论是介质本身的材料,还是上下电极材料。”这些技术都是在逐步的演进过程中的。
工艺尺寸微缩过程中,DRAM主流市场上,三星、海力士、美光的15nm DRAM都已经实现了量产。我们国家长鑫存储19nm DDR4 DRAM也已经实现了量产。“在进入1z技术节点之后,技术难度就变得非常大。”

“未来有很多新的技术可以期待。新材料方面,如果大家关注今年的IEDM,就会知道今年IGZO的研究很流行。”刘明说,“如果IGZO可以用的话,其实三维的DRAM就有望实现。另外,现在的电容材料如果改用铁电,就有望实现非易失性的DRAM。这对降低功耗就非常有意义。”说这两点,大概和刘明与微电子所现在正在进行的研究有很大的关系。

上面这项研究也是刘明及其成员在做的一项成果,“这是我们组里最近的工作,提出vertical channel-all-around IGZO FETs,实现了2T0C的DRAM;能够实现三维堆叠。我们现在做了两层。”
“这个结果是很令人振奋的,也选登了今年IEDM highlight的文章。”
除了IGZO,延续前文谈到的,对于基于铁电的非易失性DRAM实现(不过对应的PPT似乎不能公开),刘明在演讲中展示了8寸标准CMOS的HZO FeRAM晶圆,谈及“32Mb完整的1T1C HZO FeRAM芯片流片成功”,而且实现了>1e11 cycles的可靠性,虽然和一般的DRAM还不能比,但“读写速度差不多”。关键这是个非易失性DRAM,“在嵌入式应用中会非常有前景。

DRAM的另一个发展方向,典型的就是HBM die的堆叠。“通过系统集成的方法,可以显著提高带宽。当然它也有代价,它的latency并没有变化,但成本有很大的增加。”我们知道,这类方案在GPU、AI芯片等产品在数据中心、HPC已经有比较广泛的应用。
堆叠闪存情况如何?
刘明说闪存是集成电路中,最早遇到scaling down瓶颈问题的产品。“当density很高的时候,就意味着器件尺寸很小,能存的电荷数量就会很有限,读写的margin就很小。而且从存储阵列的角度来说,很高的密度会带来coupling效应,相邻单元存在更大的干扰。”于是闪存也是第一个“走出了scaling down困境,转向三维结构发展”的产品。首个3D NAND在2014年就问世了。

上面这张图是3D NAND这些年的发展。三星此前就表示,3D NAND将来甚至可以堆叠到500层。加上CTF(Charge Trap Flash)技术用silicon nitride film来储存电荷。“可靠性比原来scaling down器件要高很多。”包括用TLC、QLC等在持续提升存储密度。


3D NAND在发展中也面临不少挑战,比如随着堆叠层数增加,深孔刻蚀以及俘获层、沟道层的填充;以及这么多层堆叠,应力同样存在很大挑战;另外高密度单元,读写电流的降低、波动性等都是很具体的问题。
“创新还是要立于基本点,不外乎从基本单元和架构上下功夫。”上面这张图表现了单元结构,与集成架构方面的技术。“比如说现在也有研究用铁电层这种单层材料,来代替原有的ONO层。这样无论是vertical方向,还是lateral方向,都可以进一步地进行scaling down。”
在集成架构方面,“长江存储借鉴image sensor的技术,把存储阵列和控制逻辑做在两张wafer上。通过hybrid bonding把两个wafer bonding在一起。”我们的确在索尼的图像传感器上见到过这样的方案。这类方案就能对不同的die和电路进行更有针对性的优化,起到提高性能和效率的作用。
新型存储器的机会和挑战
关注存储器的读者,对于下图列出的各类新型存储器应该都不会陌生;其差别主要在物理原理上的不同。这些技术的研究时间实际上并不短,只不过它们并未进入主流市场。如文首所述,即便在技术特性上这些技术存在一些优势,但在成本、适用性方面,仍无法与主流存储器相较。

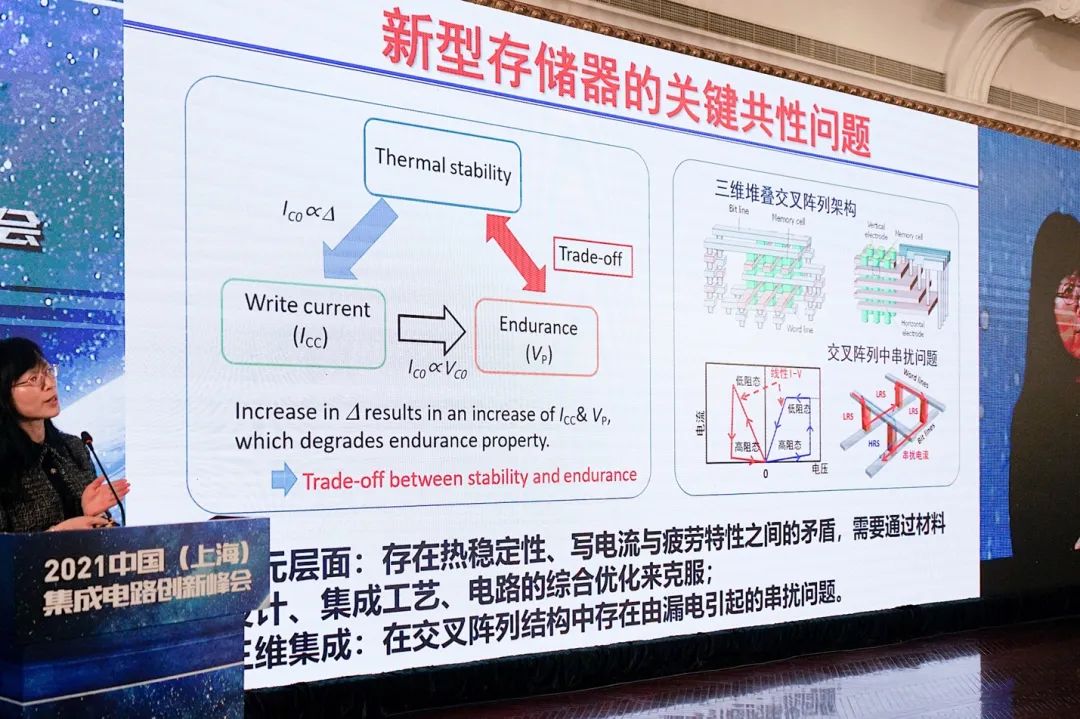
上面这张图列举了新型存储器的一些“关键共性问题”。“从单元器件上,这类存储器的thermal management就很重要,尤其是相变存储器。而且endurance和write current这些参数都是矛盾的,无法做到同步优化。”刘明表示,“比如我们说磁可以达到无数次的endurance,但这也是有条件的。”
“所以这些新型存储器,它们都有自身的问题需要解决,这是单元层面的。”
“从阵列架构来说,要提升架构、追求high density,像这样cross bar的架构非常好,但这样的架构有串扰效应。相邻位会互相干扰,这是需要解决的问题。”
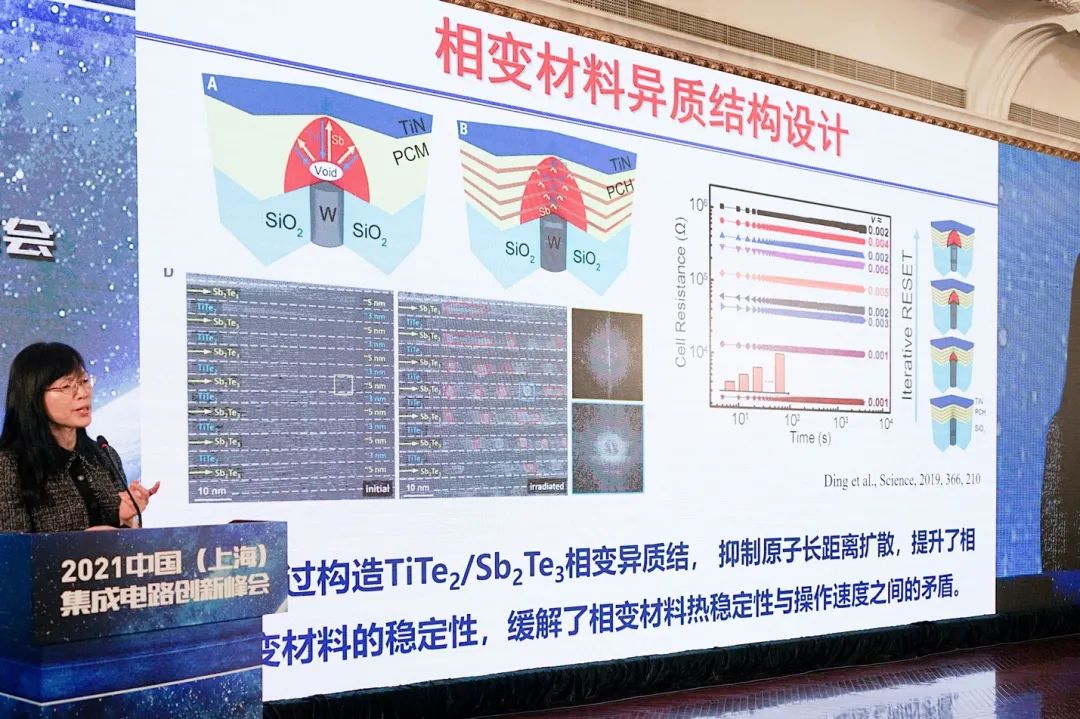

上面就是对应的一些解决方案。比如采用超晶格结构,来解决热稳定性问题(好像是2019年在Science发表的);以及提出自旋轨道矩,将原本传统STT-MRAM的读写分开等。


刘明在演讲中特别提到了3D XPoint技术(Intel将其称作Optane)。“其基本单元是相变。这个研究也已经持续很久了,但最重要的是为什么最终能够推出产品。因为它选择用OTS这种材料来做选通管。这种选通管才是导致相变能够实现这一应用的根本技术。”
3D XPoint一度被认为是弥合非易失性存储与易失性存储间性能鸿沟的重要技术,这两年Intel推的力度也很大。不过似乎这项技术的推进过程并不快,在2017年推出两层堆叠结构之后,4层堆叠产品就始终没有问世。这也可被视作,新型存储器真正普及存在巨大挑战的例子。

“我们组(中科院微电子所)一直在做阻变的研究。在独立式应用的一些场景上,我们没有选择3D XPoint这种结构。”这和成本方面的考量也应该有很大关系,“我们选择了和3D NAND一样的架构。”当然这就是另外一种挑战了。
“我们分别在2015年、2017年做了4层和8层的3D Vertical RRAM的集成。这也展示了微电子所的工艺平台还是不错的,profile非常好。事实上,我们这几年一直在往16层去做。在学术界的研究平台上,做这样的东西还是非常具有挑战性的。”
“至少在今天这样的技术状态下,新型存储器在独立式应用上,还有很漫长的路要走,有很大的挑战性。最核心的问题还是成本。Cost和density都很难与主流的3D NAND抗衡。”但刘明表示,这并不意味着新型存储器没有生存空间,嵌入式应用就是其最初的应用场景:
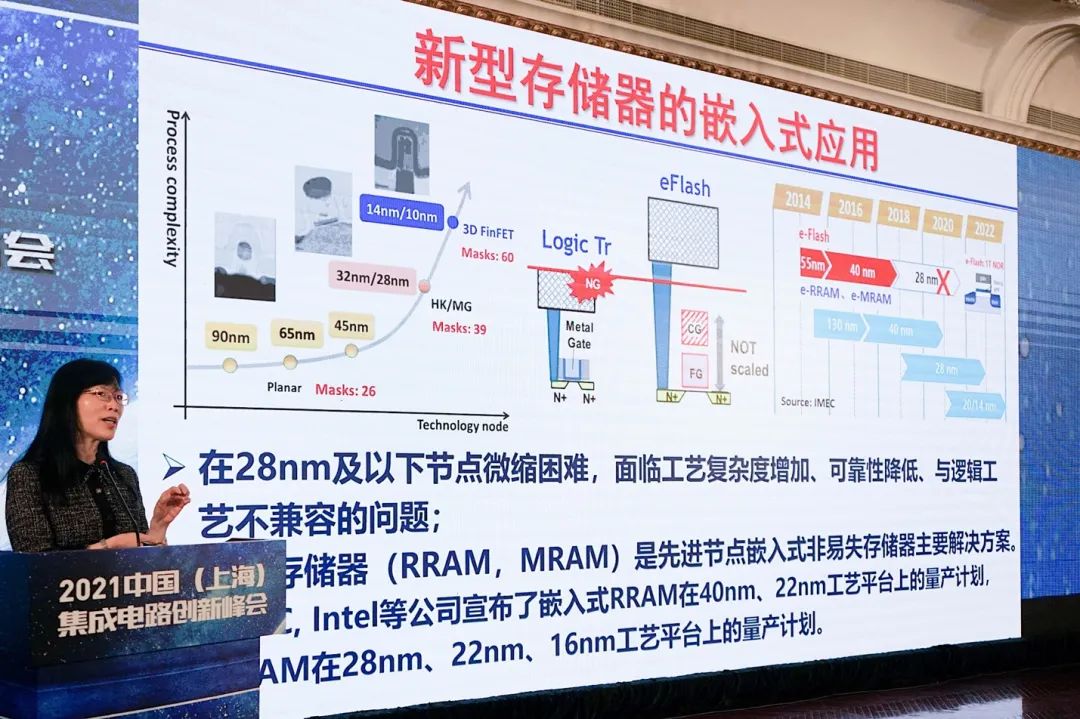
在替代eFlash的问题上,“我们知道台积电,现在无论是MRAM还是RRAM,都可以提供模块代工了。事实证明这个技术已经可以进入量产。”


刘明所在团队的这项研究得到了中芯国际和华力的支持。“我们在40/28/14nm都开发了RRAM的嵌入式集成模块。而且也得到了不错的结果。”“下一步我们在跟一些终端SoC产品企业在合作,目前有几家把它嵌入到了SoC芯片里面。我们也希望工业界能把它接过去。”


此外利用其随机性,RRAM也能应用于安全芯片,包括TRNG(随机数发生器)和PUF(物理不可克隆)芯片。“我们在去年IEDM报告的这款芯片,实现了非常高的性能。而且这些芯片经过了silicon verification。”
近存、存内与类脑计算
有关近存计算、存内计算,也都是现在比较热门的话题。这是存储器在应用侧与其他技术做融合的一个方向。因为此前我们已经介绍过近存和存内计算的概念与思路,本文不再多做重复,包括其功耗、能效方面的价值。比如存内计算,或者叫存算一体是现在很热门的话题。通常理解为在存储器中嵌入算法,存储单元本身就有计算能力,理论上消除数据存取的延迟和功耗。
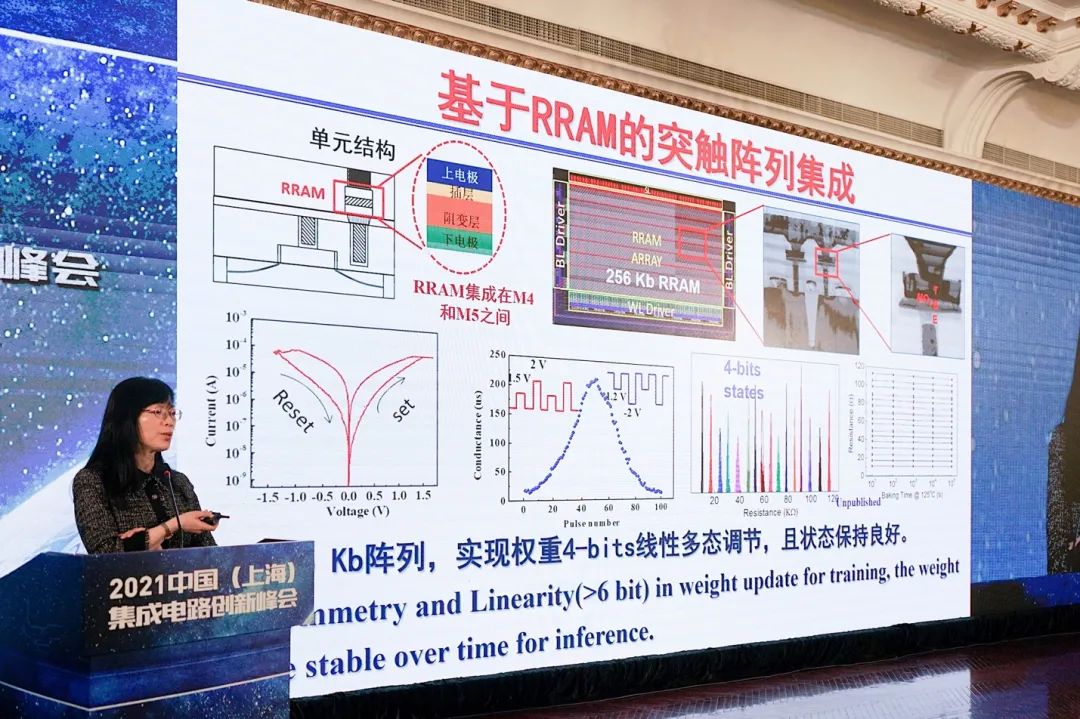
这里补充刘明这次的主题演讲中,在这部分话题中提到的一些新内容。上面这张图是“我们和华力合作研究的,基于RRAM的突触阵列,性能很不错”。

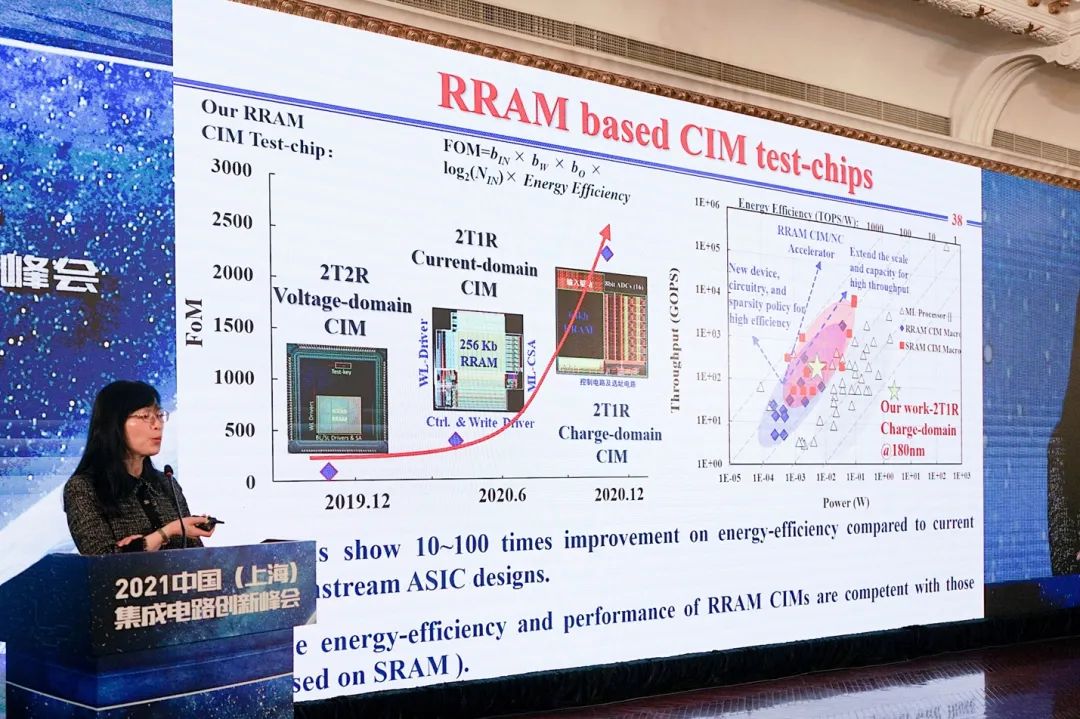
“基于这个阵列,我们也开发了几款基于RRAM的存内计算的IP核。这些IP核,有的已经完成测试。”刘明说,“国内外这几年基于RRAM的测试芯片,做存内计算的也很多。”...“我们也做出来比较好的结果。”

最后与此相关的话题,可以来谈谈类脑计算——或者说神经拟态计算(neuromorphic computing)。在这个话题上,刘明院士表示:“类脑计算是更需要时间的工作。我觉得相关类脑计算,我们现在有两个问题没有解决。”
“想要仿生人的大脑,首先要把人脑里面动力学非常丰富的神经元和神经突触,其动力学特性要抽象出来。如果连这都抽象不出来,又谈何仿真呢?”“如何编解码,其实我们并不是非常清楚。”
另外,“从计算科学的角度来看,如何用电子元器件实现动力学丰富的大规模的神经元和神经突触?相比人工智能的CNN来说,SNN资源现在是很缺乏的。无论是算法,还是数据集都没有。”“这方面更应当沉到底层的研究上去,而不是泛泛地喊口号。”“目标很高远,这需要基于我们一步一个脚印的工作。”
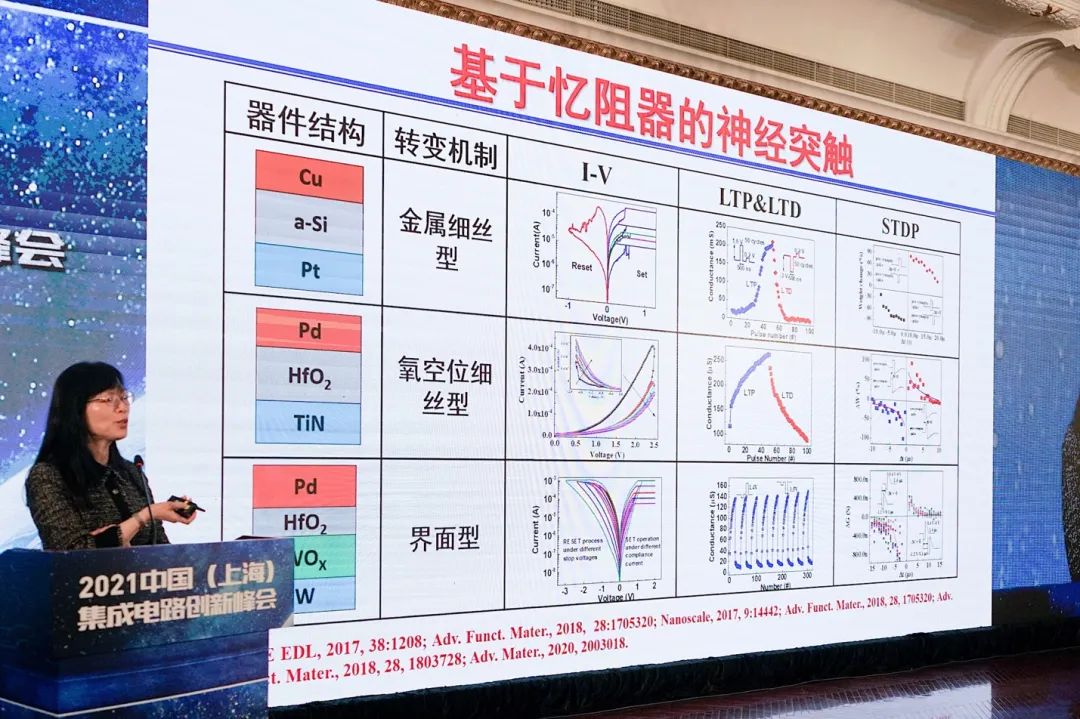
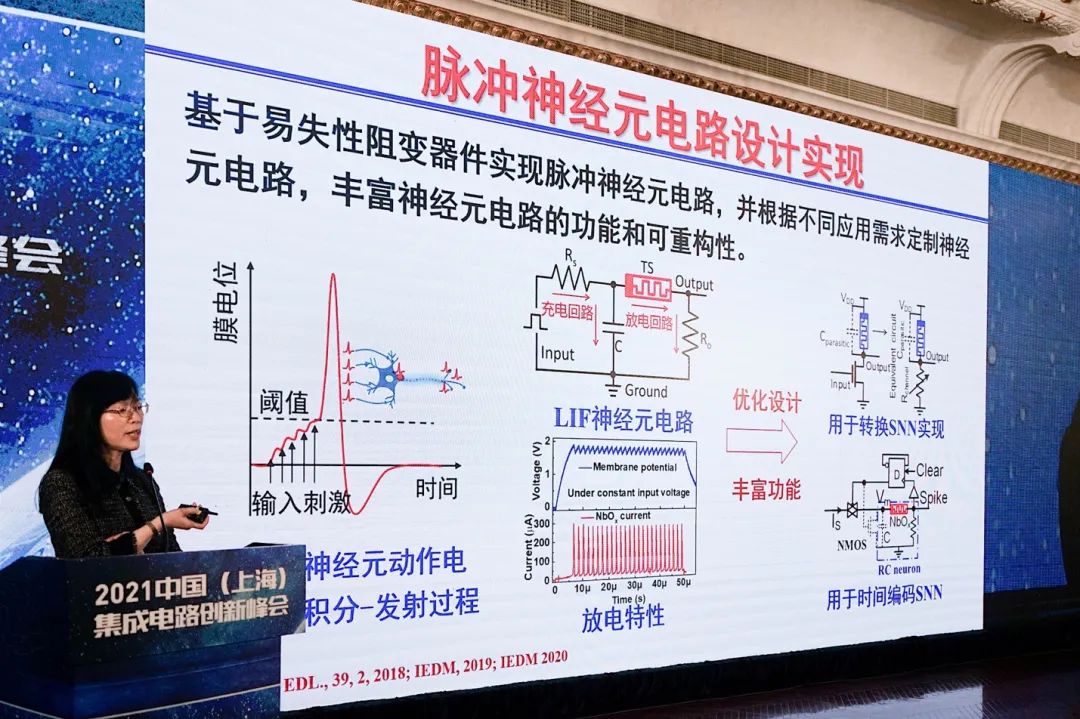
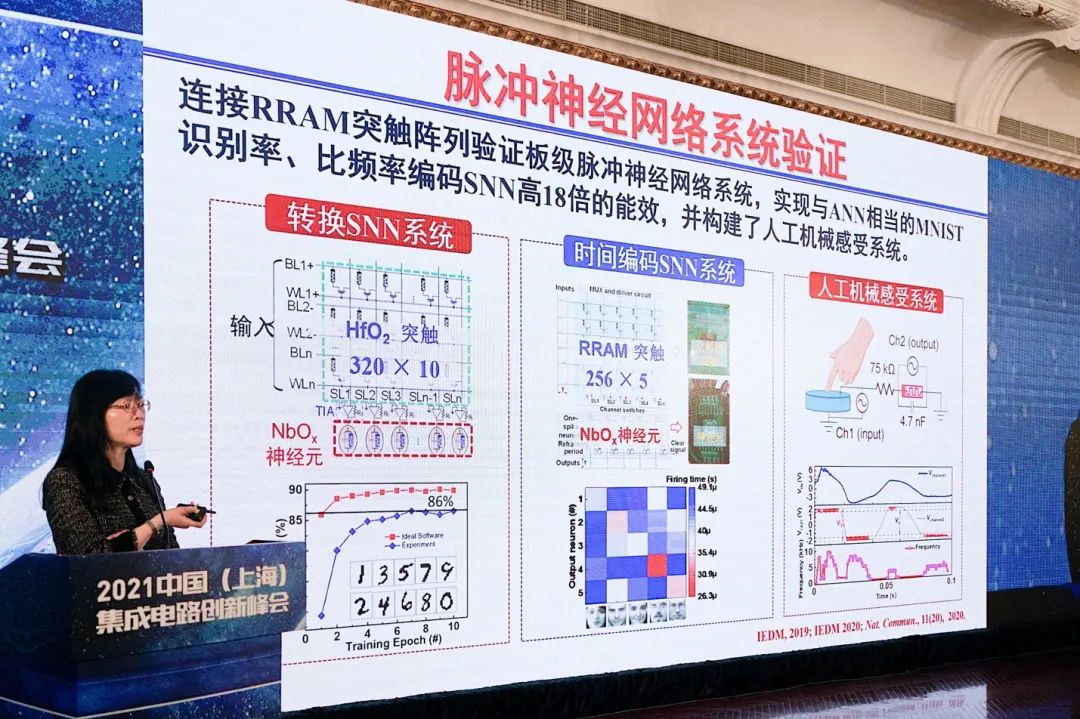

以上是目前相关于类脑计算的部分成果,包括对于构建神经元和神经突触的电路。“回过头来看全球的发展,这个领域的发展还是很快的。一开始我们是用单个器件来仿真对有限认识的人脑神经元的动力学、神经突触的一些动力学特性。慢慢发展到,我们可以把神经元和神经突触都做成阵列,用PCB板把它们集中在一起。”
“更进一步,我相信SoC芯片可以做出来,未来多核芯片也可以做出来。这方面的工作,我们也还在继续进行下去。”

